

Введение
Я рад представить свой конспект для изучения языка Python. Фактически он уже превратился в справочник, к которому можно обращаться как в период изучения языка, так и в дальнейшем, во время практического программирования. Конспект по каждой теме содержит только самый важный минимум и если представленного объема информации для вас недостаточно, то в тексте содержится множество ссылок, как на уроки с детальными разъяснениями, так и на соответствующие разделы русской документации.
Именно само содержание (оглавление) конспекта повторяет содержание курса «Добрый, добрый Python с Сергеем Балакиревым», однако материал практически полностью уникален и подготовлен в формате конспекта для закрепления знаний после прохождения соответствующей темы курса.
Предыстория. Спустя 5 месяцев после первых попыток что-то изучить в Python я решил пройти курс от Сергея Балакирева — . Этот курс выложен на платформе и он совершенно бесплатный.
Чем хорош курс: 1) видеоформат с отличным разъяснением учебного материала, 2) текстовый вариант лекций, 3) практические задания по пройденному материалу, 4) по итогу прохождения курса Вы получаете сертификат на платформе Stepik.
Я знал об этом курсе с самого начала изучения темы Python, но долго не решался к нему приступить, т.к. он казался громоздким и сложным. Начинал я с различных мини-уроков, чтения отдельных страниц разных книг, смотрел отдельные обучающие уроки на ютубе. И вроде бы отдельные знания стали появляться, но все равно была какая то бессистемность и недостаточность. В результате, спустя время, я стал смотреть курс «Добрый, добрый Python с Сергеем Балакиревым». И искренне рекомендую его всем начинающим! Если сложно сразу пройти курс, особенно при решении задач, то пропустите только самые сложные, если жалеете время из-за большого объема курса — вернитесь к курсу через какое-то время после первого погружения в python с помощью других методик.
Здесь есть важное замечание: само по себе чтение уроков или просмотр видео желаемого результата не даст — проверено лично! Принципиально важно именно решение задач по каждой теме на платформе Стёпик. На это уйдет основное время и это даст максимальный эффект. Сразу предупрежу, что в курсе некоторые задачи для тех, кто только только только приступил к знакомству с языком и программированием, реально сложные! И для новичков в этот момент python кажется совсем не добрым:-). Например для меня полный ступор был в теме «Рекурсивные функции», а в простой теме про сортировку одна задача оказалась крайне сложной из-за множества условий. Но это точно не должно стать причиной для отказа от дальнейшего прохождения курса. Что-то пропустите и вернитесь позже, если посчитаете, что знание темы вам необходимо.
Знаю по себе, что после прохождения курса (или отдельных уроков), даже несмотря на все сданные тесты, невозможно запомнить все и хочется иметь возможность при необходимости БЫСТРО вернуться к конспекту курса, чтобы он был в одном месте, на одной странице, без необходимости совершать лишние «клики» и переходы. Поэтому для себя я с самого начала и стал готовить этот материал. Лично мне этот конспект очень помог уже на этапе решения тестов курса. Конспект максимально сокращен от любой воды и содержит только сформулированные определения, синтаксисы и краткие примеры. Материал максимально переработан и в основном полностью уникальный. После каждой темы есть необходимые ссылки на подробный разбор темы от автора курса, на случай, если Вы забыли материал и Вам необходимо его вновь прослушать. Даны ссылки и на другие источники по теме.
Мой совет: если Вы хотите изучить Python для алготрейдинга, то бесплатное прохождение этого курса для Вас с самого начала то, что нужно! Не сливайте на первом этапе свой капитал на платные курсы из серии Python для алготрейдинга — лучше знать его, чем после этого курса, вы точно не станете.
Надеюсь, что и после прохождения курса Вы всегда сможете использовать этот конспект в качестве полноценного удобного справочника по Python для начинающих.
Базовые конструкции языка
Переменные, оператор присваивания, функции type и id, проверка типа данных
Данные в Python — это объект. В нем могут быть числа, строки, другие типы данных. Ссылки на объекты — это переменные.
Имена следует брать существительными (кто, что), должны быть осмысленными и отражать суть данных.
Допустимые символы в именах: первый символ – любая буква латинского алфавита a-z, A-Z и символ подчеркивания _. В качестве второго и последующих символов еще цифры 0-9.
оператор присваивания: операнд слева = операнд справа. Например x=777
b = x — обе переменные будут ссылаться на один и тот же объект 777. Переменные не хранят значения, а лишь ссылаются на них.
Каскадное присваивание: x = b = c = 777
Множественное присваивание: x, b = 777, 333
Функция type() возвращаtn тип данных.
Функция isinstance(object, classinfo) используется для проверки того, является ли указанный объект экземпляром указанного класса или классов; здесь object — объект, который вы хотите проверить, classinfo — класс или кортеж классов (или типов), с которыми вы хотите сравнить объект. Возвращает bool (False или True).
,
Числовые типы, арифметические операции
Есть три базовых типа для представления чисел:
int – для целочисленных значений;
float – для вещественных;
complex – для комплексных.
Арифметические операции
| Оператор | Описание | Приоритет |
| + | сложение | 2 |
| — | вычитание | 2 |
| * | умножение | 3 |
| /, // | деление | 3 |
| % | остаток деления | 3 |
| ** | возведение в степень | 4 |
Сложение целого числа с вещественным всегда дает вещественное значение.
Умножении целого на вещественное получается вещественное число.
Делении двух любых чисел всегда дает вещественное число
// — Деление с округлением к наименьшему целому x = 7 // 2 получим 3, а x = 7 // 2 получим -4
% — возвращает остаток от деления одного числа на другое. 10 % 3 даст 1, 9 % 5 даст 4, 9 % -5 даст -1 (в последнем примере следует взять наименьшее целое, делящееся на 5, т.е. -10, затем вычисляем разность между наименьшим, кратным 5 и -9: -9 – (-10) = 1)
** — возведение в степень. 2 ** 3 ** 2 # 512 (сначала 3 возводится в квадрат и затем, 2 возводится в степень 9). Оператор возведения в степень выполняется справа-налево. Тогда как все остальные арифметические операции – слева-направо.
Приоритеты арифметических операций
27 ** 1/3 Получим 9, т.к. приоритет у оператора возведения в степень ** — наибольший.
Если нам нужно изменить порядок вычисления, то следует использовать круглые скобки, например 27 ** (1/3)
,
Математические функции и работа с модулем math
Функция abs() позволяет вычислять модуль чисел (из отрицательных делает положительные): abs(-7.6) #7.6
Функция min() выбирает минимальное значение среди переданных ей чисел: min(1, 2, 3, 0, -5, 10) # -5
Функция max() – ищет максимальное значение: max(1, 2, 3, 0, -5, 10) # 10
Число аргументов у этих функций может быть произвольным, но не менее одного, иначе ошибка.
Функция pow() возводит числа в указанную степень: pow(6, 2) аналогично 6 ** 2
Функция round() для округления чисел: round(0.51) # 1
У этой функции имеется необязательный параметр, указывающий точность округления: round(-7.8756, 2) # -7.88
Вызов одной функции из другой. Например max(1, 2, abs(-3), -10) # 3
Модуль math
Чтобы расширить набор математических функций нужно импортировать специальный модуль math:import math
Для округления до наибольшего целого: math.ceil(5.2) # 6; math.ceil(-5.2) # -5
Для наименьшего целого: math.floor(5.99) # 5; math.floor(-5.99) # -6
Факториал числа: math.factorial(6)
Отбрасывание дробной части: math.trunc(5.8) # 5 является аналогом int(5.8)
Вычисление квадратного корня: math.sqrt(49) # 7.0
Тригонометрические функции: math.sin(3.14/2) и math.cos(0)
Константы: math.pi и math.e
,
Функции print() и input(), модуль pprint. Преобразование строк в числа int() и float()
print() – вывод данных в консоль;
input() – ввод данных из стандартного входного потока (часто клавиатуры).
print(3, 5, 7) — выведет указанные значения через пробел.
print(a * 2 + 3) — выведет результат
print(abs(a * 2 + 3)) — выведет результат
У функции имеется два необязательных именованных параметра, которые довольно часто используются в практике программирования: sep – разделитель между данными; end – завершающий символ или строка.
print(a, b, c) Пробел между значениями переменных можно поменять через параметр sep, например print(a, b, c, sep=» | «)
Второй параметр end задает окончание строки вывода и по умолчанию: end = ‘\n’ — перевод на следующую строку.
print(«Hello», end=’ ‘)
print(«World!») выведет «Hello World!»
Функция input() служит для ввода информации, как правило, с клавиатуры.
Python предлагает нам модуль pprint, который предоставляет «pretty-printing» (красивый вывод) для структур данных. Когда вы хотите напечатать сложные структуры данных (например, вложенные списки, словари), pprint может сделать вывод более организованным и легкочитаемым. В модуле есть две схожие функции pprint() и pp() , которые автоматически форматируют вывод, делая его более читаемым, особенно для больших или вложенных структур данных. Технически вы можете даже переназначить print = pprint.pprint
,
Логический тип bool. Операторы сравнения и операторы and, or, not
True – истина;
False – ложь.
4 > 7 получим False
Результат сравнения можно сохранить в переменной res = a > b
type(res) — тип bool (булевый тип), может принимать только два значения: True или False.
Операторы сравнения:
| < | сравнение на меньше |
| > | сравнение на больше |
| <= | сравнение меньше или равно |
| >= | сравнение больше или равно |
| == | сравнение на равенство |
| != | сравнение на неравенство |
Операторы not, and, or и их приоритеты
Приоритеты операторов:
| or | 1 |
| and | 2 |
| not | 3 |
Оператор not в Python логически инвертирует (обращает) значение логического выражения. Если логическое выражение x истинно, то not x будет ложно, а если x ложно, то not x будет истинно.
Оператор and в Python логически объединяет два логических выражения. Если оба выражения истинны, то результат будет истинным. Если хотя бы одно из выражений ложно, то результат будет ложным.
Оператор or в Python логически объединяет два логических выражения. Если хотя бы одно из выражений истинно, то результат будет истинным. Если оба выражения ложны, то результат будет ложным.
,
Строки и списки
Введение в строки. Базовые операции над строками
Многострочные строки используют тройные кавычки (одинарные или двойные, неважно) и в них прописывается текст, например, так:
text = »’Всем привет!
Учиться программированию никогда не поздно!»’
Если отобразить содержимое этой строки в консоли Питона, то увидим специальный символ ‘\n’:
‘Всем привет!\nУчиться программированию никогда не поздно!‘
Соединение строк + (конкатенация): s1 = «Я люблю» и s2 = «язык Python», например так s3 = s1 + s2
соединить с числом: s3 = s1 + str(5)
дублирование строк: «ха « * 5
длина строки: len(«Python»)
вхождение в строку: ‘ab’ in «abracadabra»
сравнение: ‘Кот ‘ > ‘кот’ (используется код символа)
ord('а') — это функция Python, которая возвращает числовое значение (код Unicode) соответствующее символу ‘а’ или любому другому символу, переданному в качестве аргумента. В данном случае, ord('а') вернет числовое значение, которое представляет символ ‘а’ по таблице Unicode. Значение ord('а') будет зависеть от кодировки, но в стандартной кодировке Unicode символ ‘а’ имеет значение 1072.
Список базовых операций над строками:
- + (конкатенация) – соединение строк;
- * (дублирование) – размножение строкового фрагмента;
- str() – функция для преобразования аргумента в строковое представление;
- len() – вычисление длины строки;
- in – оператор для проверки вхождения подстроки в строку;
- операторы сравнения: == != > <
- ord() – определение кода символа.
, Индексы и срезы строк

s = «ПРИВЕТ PYTHON!»
последний символ — s[len(s) — 1]
Строка относится к неизменяемым типам данных. Изменяем, например, так s2 = ‘H’ + s[1:]
Срез строки — выделенная последовательность символов
срез (РИ) s[1:3] — вернет два символа с индексами 1 и 2. Последнее значение 3 не включается в срез
В срезах можно не указывать последнее значение: s[4:]
или первое: s[:5]
или оба: s[:] — в этом случае возвращается та же самая строка.
В срезах также можно использовать отрицательные индексы: s[2:-2]
В срезах можно указывать шаг перебора символов, синтаксис: строка[start:stop:step)
отрицательный шаг влечет перебор начиная с последнего символа, например
,
Основные методы строк
| Название метода | Описание |
| String.upper() | Возвращает строку с заглавными буквами |
| String.lower() | Возвращает строку с малыми буквами |
| String.count(sub[, start[, end]]) | Определяет число вхождений подстроки в строке |
| String.find(sub[, start[, end]]) | Возвращает индекс первого найденного вхождения |
| String.rfind(sub[, start[, end]]) | Возвращает индекс первого найденного вхождения при поиске справа |
| String.index(sub[, start[, end]]) | Возвращает индекс первого найденного вхождения |
| String.replace(old, new, count=-1) | Заменяет подстроку old на new |
| String.isalpha() | Определяет: состоит ли строка целиком из буквенных символов |
| String.isdigit() | Определяет: состоит ли строка целиком из цифр |
| String.rjust(width[, fillchar = ‘ ‘]) | Расширяет строку, добавляя символы слева |
| String.ljust(width[, fillchar = ‘ ‘]) | Расширяет строку, добавляя символы справа |
| zfill() | Возвращает новую строку указанной ширины. Строка заполняется 0 с левой стороны для создания указанной ширины. str(1).zfill(2) # 01, но самый простой способ можно реализовать это с помощью f строки {1:02d} # 01 |
| String.split(sep=None, maxsplit=-1) | Разбивает строку на подстроки, основываясь на заданном разделителе. Синтаксис string.split(separator, maxsplit), где separator — это разделитель, по умолчанию используется пробел; maxsplit (необязательный параметр) — максимальное количество разбиений. |
| String.join(список) | Объединяет коллекцию в строку. синтаксис:str.join(iterable), где str — строка, которая будет использоваться в качестве разделителя; iterable — последовательность элементов, которые нужно объединить. Это может быть список, кортеж или любой другой итерируемый объект. |
| String.strip() | Удаляет пробелы и переносы строк справа и слева |
| String.rstrip() | Удаляет пробелы и переносы строк справа |
| String.lstrip() | Удаляет пробелы и переносы строк слева |
,
Спецсимволы, экранирование символов, raw-строки
строки могут содержать специальные символы.
\ — это маркер начала спецсимвола
| Обозначение | Описание |
| \n | Перевод строки. Используется для создания новой строки в тексте или выводе. После символа перевода строки следующий текст будет начинаться с новой строки. |
| \\ | Символ обратного слеша |
| \’ | Символ апострофа |
| \» | Символ двойной кавычки |
| \a | Звуковой сигнал |
| \b | Эмуляция клавиши BackSpace |
| \f | Перевод формата |
| \r | Возврат каретки. Это символ возврата каретки (carriage return) в строке, используется для перемещения курсора в начало строки без перехода на новую строку. |
| \t | Горизонтальная табуляция (размером в 4 пробела). Используется для создания равномерных отступов между элементами строки или столбцами в текстовом документе или выводе. |
| \v | Вертикальная табуляция |
| \0 | Символ Null (не признак конца строки) |
| \xhh | Символ с шестнадцатиричным кодом hh |
| \ooo | Символ с восьмиричным кодом ooo |
| \N{id} | Идентификатор из кодовой таблицы Unicode |
| \uhhhh | 16-битный символ Unicode в шестнадцатиричной форме |
| \Uhhhhhhhh | 32-битный символ Unicode в шестнадцатиричной форме |
| \другое | Не является экранированной последовательностью |
Экранирование. Экранирование используется для обозначения специальных символов в строках (символов с двойным назначением). Например для добавления символа обратного слеша в строку, следует записывать два обратных слеша подряд:
path = «D:\\Python\\Projects\\stepik\\tex1.py», при печати получим D:\Python\Projects\stepik\tex1.py
экранировать следует и кавычки s = «Марка вина \»Домашнее из смородины\»», при печати получим ‘Марка вина «Домашнее из смородины»‘
Сырые raw — строки. В Python вы можете создать «сырые» строки, которые игнорируют экранирование специальных символов. Для этого используется префикс r перед открывающей кавычкой.
например path = r«D:\Python\Projects\stepik\tex1.py»
,
Форматирование строк: метод format и F-строки
str.format(*args) — это метод format для форматирования строк в Python, который позволяет вставлять значения переменных в строку.
age = 49
name = «Сергей»
можно отформатировать включив переменные так:
«Меня зовут {0}, мне {1} и я изучаю язык Python.».format(name, age)
либо так:
«Меня зовут {myname}, мне {old} и я изучаю язык Python.».format(myname=name, old=age)
F-строки — самый удобный способ форматирования строк
f«Меня зовут {name.upper()}, мне {age} и я изучаю язык Python.»
Списки — операторы и функции работы с ними

с = list(str(v)) получаем [‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘5’, ‘6’, ‘7’, ‘8’, ‘9’, ‘0’]
- len() – определение числа элементов в списке (длина списка);
- max() – для нахождения максимального значения;
- min() – для нахождения минимального значения;
- sum() – для вычисления суммы;
- sorted() – для сортировки коллекции.
- + – соединение двух списков в один;
- * – дублирование списка;
- in – проверка вхождения элемента в список;
- del – удаление элемента списка.
,
Срезы списков и сравнение списков
Срезы списков аналогичны срезам строк.
Дополнительно следует знать особенности
Если же не указывать ни первый, ни последний индексы, то получим копию исходного списка: cities = lst[:]
Также копию списка, можно сделать с помощью рассмотренной ранее функции list: c = list(lst)
либо с помощью метода copy, например c = lst.copy()
другой вариант d = lst присваивает переменной лишь ссылку на список, но не сам объект. Поэтому переменные d и lst будут ссылаться на один и тот же список.
Т.к. списки относятся к изменяемым типам данных, то можно изменять группу элементов. Например marks[2:4] = [«хорошо», «удовлетворительно»]
Сравнение списков. Сравнивать списки можно с помощью операторов >, <, ==, !=
[1, 2, 3] == [1, 2, 3] # True
[1, 2, 3] != [1, 2, 3] # False
[10, 2, 3] > [1, 2, 3] # True при сравнении перебираются последовательно элементы, и если текущий элемент первого списка больше соответствующего элемента второго списка, то первый список больше второго и дальнейшей проверки больше не происходит.
Сравнения работают с однотипными данными. для [1, 2, 3] > [1, 2, «abc»] будет ошибка.
,
Основные методы списков
| Метод | Описание |
| append() | Добавляет элемент в конец списка |
| insert() | Вставляет элемент в указанное место списка |
| remove() | Удаляет элемент по значению |
| pop() | Удаляет последний элемент, либо элемент с указанным индексом |
| clear() | Очищает список (удаляет все элементы) |
| copy() | Возвращает копию списка |
| count() | Возвращает число элементов с указанным значением |
| index() | Возвращает индекс первого найденного элемента |
| reverse() | Меняет порядок следования элементов на обратный |
| sort() | Сортирует элементы списка |
| sequence.extend(iterable) | Расширяет последовательность sequence (например, списка, кортежа или другой последовательности) путем добавления элементов из указанного итерируемого объекта iterable (например, списка, кортежа или другой последовательности). |
Перечислим некоторые особенности, например имеем a = [1, -54, 3, 23, 43, -45, 0]
Метод append ничего не возвращает, а меняет сам список.
Метод вставки a.insert(3, -1000) — указываем индекс вставляемого элемента и далее значение самого элемента.
Метод remove удаляет элемент по значению: a.remove(True) или a.remove(‘hello’) — находит первый подходящий элемент и удаляет его, остальные не трогает. Если же указывается несуществующий элемент — получим ошибку. Кроме того a.remove(True) удалит как True, так и 1, а a.remove(False) удалит как False, так и 0 (речь о первом найденном элементе).
a.pop() выполняет удаление последнего элемента и при этом, возвращает его значение. Также в этом методе можно указывать индекс удаляемого элемента, например: a.pop(3)
Если нам нужно очистить весь список – удалить все элементы, то можно воспользоваться методом:
a.clear() получаем пустой список.
count позволяет найти число элементов с указанным значением: c.count(1)
метод index для получения индекса определенного значения c.index(-45) — берется индекс только первого найденного элемента. Можем указать стартовое значение для поиска: c.index(23, 1, 5) — ищем число 23 с 1-го индекса и по 5-й не включая его. Если элемент не находится — ошибка, лучше сделать проверку 23 in c[1:3]
c.sort() — сортировка элементов списка по возрастанию. Для сортировки по убыванию c.sort(reverse=True)
Отличие метода sort() от ранее рассмотренной функции sorted() в том, что метод меняет сам список, а функция sorted() возвращает новый отсортированный список, не меняя начальный.
,
Вложенные списки, многомерные списки
Вложенные списки — это списки, содержащие другие списки в качестве своих элементов. Таким образом, каждый элемент внешнего списка может быть списком сам по себе.
например spis = [[1, 2, 3], [4, «РФ», 6], [7, 8, 9]] и чтобы получить «РФ» используем print(spis[1][1])
Можно создавать списки с любым количеством уровней вложенности и структуры в зависимости от нужд вашей программы.
,
Условные операторы, циклы, генераторы списков
Условный оператор if. Конструкция if-else
Условный оператор if используется для выполнения определенного блока кода только в том случае, если определенное условие истинно. Конструкция if-else позволяет также выполнить другой блок кода, если условие не выполняется, т.е. она позволяет выбирать между двумя различными путями выполнения кода в зависимости от выполняемого условия.
x = 3
if x > 5:
print("x больше 5")
else:
print("x меньше или равен 5"),
Вложенные условия и множественный выбор. Конструкция if-elif-else
Вложенные условия в Python позволяют проверять дополнительные условия внутри других условий. Это полезно, когда вы хотите уточнить или добавить дополнительные проверки, которые должны выполняться только при определенных условиях.
Пример поиска наибольшего среди трех чисел a, b и c:
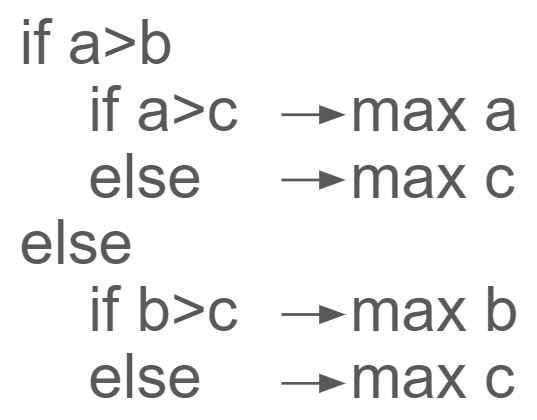
Степень вложенности условий может быть любой, но на практике нормальным считается вложения до трех. Если это не так, то скорее всего стоит пересмотреть структуру программы.
Оператор elif в Python (который означает «else if») используется для проверки дополнительных условий, если предыдущее условие в блоке if не выполнилось. Он позволяет проверить несколько различных условий и выполнить соответствующий блок кода, если условие истинно.
Оператор elif может быть использован несколько раз для проверки дополнительных условий, и только первый выполненный блок кода будет выполнен. Если ни одно из условий не выполняется, то блок кода в else будет выполнен, если он присутствует.
Оператор else используется для выполнения блока кода, если все предыдущие условия были ложными.
Обязательная последовательность if - elif - else
Python использует отступы для определения блоков кода. Все строки с одинаковым отступом после if, elif или else будут считаться частью того же блока кода.
,
Тернарный условный оператор. Вложенное тернарное условие
Тернарный оператор автоматически возвращает результат.
Тернарный условный оператор в Python представляет собой сокращенную версию условного оператора if-else и имеет следующий синтаксис:
<значение 1> if <условие> else <значение 2>. Здесь он возвращает значение 1, если условие истинно, а иначе – значение 2.
Вложенный тернарный оператор (вложенное тернарное условие) — это использование тернарного оператора внутри другого тернарного оператора. Это позволяет создавать более сложные логические проверки с помощью тернарных операторов.
Например, так: result = «Число больше 5» if x > 5 else («Число равно 5» if x == 5 else «Число меньше 5»)
,
Оператор цикла while
Циклы позволяют реализовывать некие повторяющиеся действия. Пока истинно условие, цикл работает, как только условие становится ложным – цикл завершается.
Оператор цикла while в Python выполняет блок кода, пока указанное условие истинно. Например:
i = 1
while i <= 5: # Заголовок цикла
# Тело цикла
print(i)
i += 1Однократное выполнение тела цикла в программировании называют итерацией.
В условиях цикла лучше использовать < или >, чем <= или >= , т.к. последние работают немного медленней. Это только рекомендация, если она легко выполнима.
,
Операторы циклов break, continue и else
Оператор break используется для немедленного (досрочного) выхода из цикла for или while и продолжения выполнения программы с следующей строкой после цикла.
for i in range(1, 101):
if i == 15:
break
print(i)В этом примере цикл for проходит через числа от 1 до 101. Когда число равно 15, оператор break вызывает немедленное выходы из цикла, и выполнение программы продолжается с последующей строкой после цикла. В данном случае, это вывод чисел 1, 2, 3,…. 15 и завершение программы.
Оператор continue используется для пропуска остальной части тела цикла for и перехода к следующему итерации.
for i in range(1, 11):
if i % 2 == 0:
continue
print(i)В этом примере цикл for проходит через числа от 1 до 10. Когда число делится на 2 без остатка, оператор continue пропускает остальной код внутри цикла и переходит к следующей итерации. В результате выводятся нечетные числа 1, 3, 5, 7, 9.
Оператор else используется с циклом for и while и выполняется, когда цикл завершается нормально, т.е., не был прерванным оператором break.
Про оператор else ранее уже была речь, когда рассматривали условные операторы. У циклов оператор else также есть. Оператор else используется с циклом while и выполняется, когда цикл завершается нормально (штатно), т.е., не был прерванным оператором break.

,
Оператор цикла for. Функция range()
Оператор цикла for является одним из самых распространенных способов организации циклов в Python. Он используется для итерации по последовательностям элементов (например, списка, кортежа, строк) или любым другим итерируемым объектам.
Он имеет следующий синтаксис:
for <переменная> in <итерируемый объект>:
оператор 1
оператор 2
…
оператор N
Пример:
my_list = [10, 20, 30, 40, 50]
for item in my_list:
print(item)переменная item будет поочередно содержать каждый элемент списка my_list, и на каждой итерации будет выполняться блок кода внутри цикла. Таким образом, на каждой итерации будет выводиться элемент списка.
Для перебора не элементов списка, а индексов лучше всего использовать функцию range() . Вот пример for цикла, который перебирает буквы алфавита:
alphabet = ["А", "Б", "В","Г","Д","Е","Ё","Ж","З","И","Й","К","Л","М","Н","О","П","Р","С","Т","У","Ф","Х","Ц","Ч","Ш","Щ","Ъ","Ы","Ь","Э","Ю","Я"]
for index in range(len(alphabet)):
print("Буква №:", index + 1, "Значение:", alphabet[index])получим:
Буква №: 1 Значение: А
Буква №: 2 Значение: Б
….
Буква №: 33 Значение: Я
в примере используется цикл for с функцией range(len(alphabet)), чтобы перебрать каждый элемент списка alphabet. Внутри цикла выводится номер буквы (с учетом нумерации с 1) и саму букву, используя индексирование списка alphabet[index].
Подробнее о самой функции range() в Python: она используется для создания последовательности чисел. В общем виде range() может выглядеть так:
range(start, stop, step) , где:
start: Начальное значение последовательности (включительно); stop: Конечное значение последовательности (не включительно); step: Шаг, с которым изменяется каждое следующее число (по умолчанию 1).
Функция range() принимает только целые числа int в качестве аргументов. Если вам нужно использовать дробный шаг, вы можете вместо этого использовать целое число и затем преобразовать его в нужный дробный шаг в вашем генераторе.
Функция range() возвращает специальный объект, называемый «range object» (объект диапазона), который представляет собой последовательность чисел. Однако этот объект не является списком в полном смысле и не хранит все числа в памяти как список. Вместо этого он генерирует числа по мере необходимости.
Если нужно получить список чисел, можно преобразовать объект диапазона в список с помощью функции list():
my_range = range(5)
my_list = list(my_range)
print(my_list) # [0, 1, 2, 3, 4]к,
Функция enumerate()
enumerate() — это встроенная функция Python, которая позволяет перебирать элементы последовательности (например, списка, кортежа, строки) и возвращать индекс каждого элемента вместе с самим элементом. Функция очень удобна при работе с коллекциями данных, когда необходимо иметь доступ как к элементу, так и к его индексу во время итерации.
Синтаксис: индекс, значение = enumerate(объект)
Функция enumerate() также может принимать дополнительный аргумент start, который определяет начальное значение индекса. По умолчанию индекс начинается с 0, но с помощью аргумента start можно задать другое начальное значение.
например:
my_list = ["яблоко", "банан", "вишня"]
for index, value in enumerate(my_list, start=1):
print(index, value)получаем:
1 яблоко
2 банан
3 вишня
,
Итератор и итерируемые объекты. Функции iter() и next()
Итерируемые объекты в Python — это объекты, которые могут быть перебраны с помощью цикла. Для работы с итерируемыми объектами в Python используется протокол итераторов. Примеры итерируемых объектов в Python включают в себя списки, кортежи, словари и строки.
Итератор — это объект, который обеспечивает итерацию (последовательный проход) по элементам итерируемого объекта.
Функция iter в Python используется для создания итератора для итерируемого объекта, такого как список, кортеж, строка и т.д. Созданный итератор может быть использован для последовательного доступа к элементам итерируемого объекта с помощью функции next.
Пример использования функции iter для создания итератора:
my_list = [1, 2, 3, 4, 5]
my_iter = iter(my_list) # создание итератора для списка
print(next(my_iter)) # выводит первый элемент списка
print(next(my_iter)) # выводит второй элемент списка
# и так далееЕсли продолжать вызывать print(next(my_iter)) , то после достижения конца итерируемого объекта, будет вызвано исключение StopIteration. Это происходит потому, что когда итератор достигает конца итерируемого объекта и больше нет элементов для возврата, вызов метода __next__() приводит к возбуждению исключения StopIteration, сигнализирующего о завершении итерации.
Для более безопасной итерации по элементам итератора можно использовать конструкцию цикла for, которая автоматически обрабатывает исключение StopIteration и завершает итерацию, когда все элементы были пройдены.
next(), то он будет возвращен вместо исключения StopIteration. Вот пример:my_list = [1, 2]
my_iter = iter(my_list)
# Использование второго аргумента в функции next()
print(next(my_iter, "Элемент не найден")) # выводит первый элемент списка
print(next(my_iter, "Элемент не найден")) # выводит второй элемент списка
print(
next(my_iter, "Элемент не найден")
) # выводит "Элемент не найден", так как достигнут конец итерациии в заключении еще пример использования итератора для печати введенного числа через пробелы:
for w in iter(input()): # 4587
print(w, end=" ") # 4 5 8 7,
Вложенные циклы. Примеры задач с вложенными циклами
Вложенные циклы — это когда один цикл находится внутри другого цикла. Такие циклы используются для обработки двумерных структур данных, перебора всех возможных комбинаций элементов, или выполнения действий над вложенными структурами данных. Вложенные циклы могут быть использованы для обработки матриц, управления многомерными данными, генерации перестановок и комбинаций, и для других сценариев, где необходимо работать с многократными уровнями данных или действий.
Вложенные циклы могут быть созданы с использованием любого типа цикла, включая:
— Циклы for: Вложенные циклы for могут быть использованы для обработки элементов вложенных структур данных, перебора комбинаций или выполнения действий над многомерными данными.
— Циклы while: Вложенные циклы while могут использоваться для повторения действий до выполнения определенного условия, как внутри внешнего, так и внутри вложенного цикла.
Оба типа циклов могут быть вложенными, и каждый внутренний цикл будет полностью выполнен для каждой итерации внешнего цикла.
В Python, степень вложенности циклов теоретически не ограничена. Но обычно вложенные циклы используются с небольшой степенью вложенности — до трех уровней вложенности.
,
Генераторы списков
Генераторы списков — это сокращенный способ создания списков в Python, который позволяет создавать списки без явного использования циклов. Генератор циклов работает быстрее, чем обычный цикл for или while. Их удобно использовать для следующих целей:
- Эффективное создание списков без необходимости использования циклов, создание новых списков на основе существующих списков
- Удобное применение операций к каждому элементу списка
- Фильтрация элементов списка и др.
Общий синтаксис: new_list = [(выражение) for элемент in (итерируемый объект или итератор) if условие]
Итерируемый объект — это объект, который можно пройти по его элементам последовательно. Это означает, что он может быть перемещен к следующему элементу в последовательности. Например, список является итерируемым объектом, и вы можете перемещаться по его элементам с помощью цикла for.
Итератор — это объект, который представляет собой позицию в коллекции и позволяет получить текущий элемент и переместиться к следующему элементу. Итераторы обычно используются в сочетании с циклами for для итерации по элементам коллекции.
Примеры:
x = 7
print([1 for x in range(x)]) # Создание списка [1, 1, 1, 1, 1, 1, 1]
print([7] * x) # хотя удобнее так
print(
[x % 2 == 0 for x in range(x)]
) # Создание списка результата проверки четное/нечетное [True, False, True, False, True, False, True]
print(
["четное" if x % 2 == 0 else "нечетное" for x in range(x)]
) # ['четное', 'нечетное', 'четное', 'нечетное', 'четное', 'нечетное', 'четное']
print([x**2 for x in range(x)]) # Создание списка x в квадрате [0, 1, 4, 9, 16, 25, 36]
print([x for x in range(x) if x % 2 == 0]) # Создание списка четных из диапазона
print(
[word.upper() for word in ["Привет", " ", "мир!"]]
) # Создание списка с верхним регистром
print(
[int(x) for x in input().split()]
) # Создание списка целых чисел из введенных в одну строку через пробел
print(
[x for x in "Изучаем"]
) # Создание списка символов из строки ['И', 'з', 'у', 'ч', 'а', 'е', 'м'],
Вложенные генераторы списков
Мы можем записывать любое число циклов for в генераторах списков. Вложенные генераторы списков — это способ создания списков, используя выражение внутри другого выражения списка. Это позволяет создавать списки более компактно и читаемо.
new_list = [[(выражение) for элемент in (итерируемый объект или итератор) if условие] for (счетчик) in (итерируемый объект или итератор) ] или так
new_list = [(выражение) for элемент in (итерируемый объект или итератор) if условие for элемент in (итерируемый объект или итератор) ]
Приведем примеры:
# создание матрицы
matrix = [[i * j for j in range(1, 4)] for i in range(1, 4)]
print(matrix)
# Преобразование вложенного списка в одноуровневый список
list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
new_list = [x for row in list for x in row]
print(new_list)
# Создание списка списков с использованием условия во внутреннем генераторе
# создаем списки четных чисел от 1 до 5 для каждого элемента внешнего списка
numbers = [[i for i in range(1, 6) if i % 2 == 0] for j in range(3)]
print(numbers)
# переворот (трансформация) матрицы
lst_in = [[11, 22, 33], [44, 55, 66], [77, 88, 99], [100, 102, 103]]
tt = [[row[x] for row in lst_in] for x in range(len(lst_in[0]))]
for row in tt:
print(*row),
Словари, кортежи и множества
Словари (dict). Базовые операции над словарями
Словари в Python — это структуры данных, которые позволяют хранить пары ключей и соответствующих им значений. Словари являются изменяемыми типами данных. Ключи в словаре должны быть уникальными, а значения могут быть любого типа данных. В Python словари создаются с помощью фигурных скобок {} и содержат ключи и значения, разделенные двоеточием.
Синтаксис: {key1: value1, key2: value2, …, keyN:valueN}, где
"key1", "key2", "keyN" — ключи словаря, они могут быть строками, числами или другими неизменяемыми объектами; : — двоеточие используется для разделения ключа и его соответствующего значения; "value1", "value2", "valueN" — значения, соответствующие ключам в словаре.
Ключи рекомендуется использовать в виде строк. В ключах используйте строчные буквы с подчеркиванием между словами. Например: first_name, last_name, age. Не используйте специальные символы, кроме символа подчеркивания. В тоже время в качестве ключей могут быть использованы любые неизменяемые типы, например булевы значения. Хотя чаще всего используются строки или числа. На значения словаря никаких ограничений не накладывается.
Словарь при итерировании, выдает только ключи.
Для обращения к элементу словаря в Python используется синтаксис dict_name[key], где dict_name — имя словаря, а key — ключ, по которому нужно получить значение. Если ключ отсутствует в словаре, будет сгенерировано исключение KeyError.
Пример:
my_dict = {"key1": "one", "key2": "two", 3: "three"}
print(my_dict["key1"]) # oneДля присваивания значения элементу словаря в Python используется синтаксис dict_name[key] = value, где dict_name — имя словаря, key — ключ, к которому нужно присвоить значение, и value — значение, которое нужно присвоить.
my_dict["name"] = "Alice" # добавляем новую пару ключ-значение
my_dict["age"] = 50 # добавляем новую пару ключ-значение
my_dict["key2"] = "ДВА" # изменяем значение по ключу "key2"
print(my_dict) # {'key1': 'one', 'key2': 'ДВА', 3: 'three', 'name': 'Alice', 'age': 50}len() — количество элементов в словаре
del — удаление пары ключ-значение
in — проверка наличия ключа в словаре
dict() — создает пустой словарь.
Функция dict() очень удобна и позволяет создавать словари из различных структур данных или набора ключей и значений.
print(len(my_dict)) # 5
del my_dict["age"]
print("age" in my_dict) # False
print("age" not in my_dict) # True
print(dict()) # {}
my_dict = dict(name="Лев", age=6, status="малыш")
print(my_dict) # {'name': 'Лев', 'age': 6, 'status': 'малыш'}
pairs = [("a", 1), ("b", 2), ("c", 3)]
my_dict = dict(pairs)
print(my_dict) # {'a': 1, 'b': 2, 'c': 3}
keys = ["name", "age", "city"]
values = ["Александр", 25, "Кострома"]
my_dict = dict(zip(keys, values))
print(my_dict) # {'name': 'Александр', 'age': 25, 'city': 'Кострома'},
Методы словаря, перебор элементов словаря в цикле
| Название метода | Описание |
| dict.fromkeys(iterable[, value]) | Создание словаря dict со значениями ключей по умолчанию |
| dict.clear()GG | Производит удаление всех элементов из словаря dict, получаем {} |
| dict.copy() | Создает копию словаря. Также копию можно сделать с помощью dict: copied_dict = dict(orig_dict) |
| dict.get(key[, default]) | Получение значения из словаря по заданному ключу, если ключ отсутствует по умолчанию возвращает None. Также получить значение по ключу можно с помощью dict[key] |
| dict.setdefault(key[, default]) | Получения значения из словаря по заданному ключу, при его отсутствии метод добавляет ключ со значением по умолчанию или None. |
| dict.pop(key[, default]) | Вернет значение ключа key, а также удалит его из словаря dict. Если ключ не найден, то вернет значение по умолчанию default. Если оно не задано и ключ key отсутствует в словаре dict, то возникает ошибка KeyError. |
| dict.popitem() | Удаляет и возвращает двойной кортеж (key, value) из словаря dict. Пары возвращаются с конца словаря. |
| dict.keys() | Возвращает новый список-представление всех ключей dict_keys, содержащихся в словаре dict. |
| dict.values() | Возвращает новый список-представление всех значений dict_values, содержащихся в словаре dict. |
| dict.items() | Возвращает новый список-представление dict_items пар элементов словаря dict, такой как (key, value), фактически список кортежей вида (key, value), состоящий из элементов словаря. |
| dict.update([other]) | Обновляет/дополняет словарь dict с помощью пар ключ-значение из other, перезаписывая существующие ключи новыми значениями из other. Если ключ в словаре отсутствует, то он добавляется. Метод ничего не возвращает. |
Метод dict.fromkeys() встроенного класса dict() создает новый словарь с ключами из последовательности iterable и значениями, установленными в value. Значения по умолчанию None.
keys = ["29", "30", "31", "32", "33"]
my_dict1 = dict.fromkeys(keys)
print(my_dict1) # {'29': None, '30': None, '31': None, '32': None, '33': None}
# Использование fromkeys для создания словаря с ключами из списка и указанным значением по умолчанию
my_dict2 = dict.fromkeys(keys, "код региона рф")
print(my_dict2) # {'29': 'код региона рф', '30': 'код региона рф', '31': 'код региона рф', '32': 'код региона рф', '33': 'код региона рф'}clear() используется для удаления всех элементов из словаря. После вызова этого метода словарь становится пустым.copy() используется для создания копии словаря, содержащей те же ключи и значения, что и исходный словарь. Копию словаря также можно создать с помощью функции dict(), которой необходимо передать исходный словарь в качестве аргумента.my_dict2.clear()
print(my_dict2) # {}
my_dict3 = my_dict1.copy()
print(my_dict3) # {'29': None, '30': None, '31': None, '32': None, '33': None}
my_dict4 = dict(my_dict3)
print(my_dict4) # {'29': None, '30': None, '31': None, '32': None, '33': None}Чтобы обратиться к значению по ключу в словаре, вы можете использовать квадратные скобки [] и указать ключ внутри них. Например, чтобы получить значение для ключа «cat» из словаря dict, вы можете сделать следующее: value = dict[«cat»] . Если вы попытаетесь обратиться к ключу, которого нет в словаре, например dict["cat123"], то это вызовет ошибку KeyError, так как ключ «cat123» отсутствует в словаре dict. Чтобы избежать ошибки, можно использовать метод get(), который позволяет указать значение по умолчанию, которое будет возвращено, если ключ не найден в словаре.
Метод get() используется для получения значения из словаря по заданному ключу. Он позволяет избежать ошибки KeyError, если ключ отсутствует в словаре, возвращая вместо этого указанное значение по умолчанию или None, если значение по умолчанию не указано. Например value = dict.get("cat123", "Ключ не найден")
Метод setdefault() используется для получения значения из словаря по заданному ключу. Если ключ отсутствует в словаре, этот метод также добавляет указанный ключ со значением по умолчанию или None, если значение по умолчанию не указано.
Метод pop() используется для удаления элемента из словаря по заданному ключу и возвращения соответствующего значения. Если ключ не найден, метод pop() вызовет исключение KeyError или вернет значение по умолчанию, если оно было указано.
Метод popitem() используется для удаления и возврата произвольной пары ключа и значения из словаря. Этот метод удаляет элемент из словаря и возвращает кортеж, содержащий удаленный ключ и значение. В отличие от метода pop(), который принимает ключ в качестве аргумента, popitem() не принимает аргументов и удаляет последнюю пару ключ-значение из словаря.
dict_city = {"Москва": "Moscow", "Сочи": "Sochi"}
print(dict_city.get("Сочи")) # Sochi
print(dict_city.get("Кукукино", "отсутствуют данные")) # отсутствуют данные
print(dict_city.setdefault("Сочи")) # Sochi
print(dict_city.setdefault("Кукукино", "Kukukino")) # Kukukino
print(dict_city) # {'Москва': 'Moscow', 'Сочи': 'Sochi', 'Кукукино': 'Kukukino'}
print(dict_city.pop("Киров", False)) # False
print(dict_city.pop("Кукукино")) # Kukukino
print(dict_city) # {'Москва': 'Moscow', 'Сочи': 'Sochi'}
print(dict_city.popitem()) # возвращает ('Сочи', 'Sochi')
print(dict_city) # Последняя пара ключ-значение удалены, осталось {'Москва': 'Moscow'}Метод keys() используется для получения представления всех ключей (keys) из словаря в виде объекта типа dict_keys. Этот метод возвращает представление, которое содержит все ключи словаря. Важно отметить, что объект dict_keys является представлением и не является списком, хотя содержит все ключи словаря. Если требуется список ключей, можно использовать функцию list() для преобразования dict_keys в список.
Метод values() используется для получения представления всех значений (values) из словаря в виде объекта типа dict_values. Этот метод возвращает представление, которое содержит все значения словаря. Объект dict_values также является представлением и не является списком, хотя содержит все значения словаря.
Метод items() используется для получения представления всех пар ключ-значение (items) из словаря в виде объекта типа dict_items. Этот метод возвращает представление, которое содержит все пары ключ-значение словаря в виде кортежей.
Подобно методам keys() и values(), объект dict_items также является представлением и не является списком, хотя содержит все пары ключ-значение словаря в виде кортежей. Если требуется список пар ключ-значение, можно использовать функцию list() для преобразования dict_items в список.
dict_city = {"Москва": "Moscow", "Сочи": "Sochi", "Кукукино": "Kukukino"}
kl = dict_city.keys()
print(kl) # dict_keys(['Москва', 'Сочи', 'Кукукино'])
print(type(kl)) # <class 'dict_keys'>
print(list(kl)) # ['Москва', 'Сочи', 'Кукукино']
print(list(dict_city.values())) # ['Moscow', 'Sochi', 'Kukukino']
print(
dict_city.items()
) # dict_items([('Москва', 'Moscow'), ('Сочи', 'Sochi'), ('Кукукино', 'Kukukino')])Метод update() используется для обновления значений словаря, добавляя пары ключ-значение из другого словаря other или из итерируемого объекта, содержащего пары ключ-значение. Если пары ключ-значение в other уже существуют в исходном словаре, то значения этих ключей будут обновлены. Если ключи отсутствуют в исходном словаре, они будут добавлены. Метод update() предоставляет удобный способ объединить два словаря в Python.
Также объединить словари можно с помощью оператора ** (double star): Оператор ** позволяет распаковать словари в качестве аргументов при объединении. Синтаксис: new_dict = {**dict1, **dict2} Создается новый словарь. Значения дублирующих ключей из второго словаря перезапишут значения ключей с теми же ключами в первом словаре.
dict_city1 = {"Москва": "Moscow", "Сочи": "Sochi", "Кукукино": "Kukukino"}
dict_city2 = {"Ярославль": "Yaroslavl", "Кукукино": "нет такого города"}
city = dict_city1 | dict_city2
print(
city
) # {'Москва': 'Moscow', 'Сочи': 'Sochi', 'Кукукино': 'нет такого города', 'Ярославль': 'Yaroslavl'}
city_ = {**dict_city2, **dict_city1}
print(
city_
) # {'Ярославль': 'Yaroslavl', 'Кукукино': 'Kukukino', 'Москва': 'Moscow', 'Сочи': 'Sochi'}
dict_city1.update(dict_city2)
print(
dict_city1
) # {'Москва': 'Moscow', 'Сочи': 'Sochi', 'Кукукино': 'нет такого города', 'Ярославль': 'Yaroslavl'},
Кортежи (tuple) и их методы
Кортеж (tuple) — это неизменяемая последовательность элементов. Он может содержать элементы различных типов и создается с помощью круглых скобок. Они аналогичны спискам, но это неизменяемый тип данных.
пример: my_tuple = (1, ‘hello’, 3.14)
Кортеж занимает памяти почти в 2 раза меньше, чем списки.
Создание кортежа возможно используя пару скобок для обозначения пустого кортежа (); используя запятую для одиночного кортежа: a, или (a,); разделяя элементы запятыми a, b, c или (a, b, c). Важно, что запятая создает кортеж, скобки необязательны, за исключением пустого кортежа. Создание пустого кортежа () или tuple().
Для создания кортежа с дублированием элементов используется оператор умножения ‘ * ‘.
Кортеж можно распаковать в переменные, однако если число переменных будет отлично от числа элементов кортежа, то возникнет ошибка. Подобная распаковка кортежа работает с любыми итерируемыми объектами.
my_tuple = (1, "hello", 3.14)
a, b, c = my_tuple
print(a, b, c) # 1 hello 3.14
x, y = 1, 2
q, w, e, r = "вода"
my_tuple_ = (1,) * 5
print(my_tuple_) # (1, 1, 1, 1, 1)
my_tuple[0]. Можно также использовать срезы, например my_tuple[0:3]. Удалять элемент кортежа (del) нельзя.my_tuple = (1, "hello", 3.14)
my_tuple2 = ([66, 55, 44], "Пайтон")
tupl = my_tuple + my_tuple2
print(tupl) # (1, 'hello', 3.14, [66, 55, 44], 'Пайтон')
tupl_3 = ("Ура", "весна пришла") * 2
print(tupl_3) # ('Ура', 'весна пришла', 'Ура', 'весна пришла')my_list = [1, 2, 3]
my_tuple = tuple(my_list)
print(my_tuple) # (1, 2, 3)
my_list = list(my_tuple)
print(my_list) # [1, 2, 3]count() в Python используется для подсчета количества вхождений определенного элемента в кортеже. Он возвращает число вхождений данного элемента в кортеж. index() в Python используется для поиска индекса первого вхождения определенного элемента в кортеже. Он возвращает индекс этого элемента, если он найден. Если элемент не найден, то будет вызвано исключение ValueError. count = (45,4,567,87,4,56,4,).count(4)
print(count) #3
my_tuple = (456,65,45,4,32,3,6)
index = my_tuple.index(6)
print(index) #6также см.
Чтобы понять в каком случае Вам стоит использовать кортеж вместо списка исходите из ключевых отличий между ними:
- Изменяемость: Кортежи являются неизменяемыми структурами данных, что означает, что их элементы не могут быть изменены после создания кортежа. Списки являются изменяемыми структурами данных, позволяющими добавлять, удалять и изменять элементы в списке.
- Синтаксис: Кортежи объявляются с использованием круглых скобок
(), а списки с использованием квадратных скобок[]. - Скорость: Поскольку кортежи являются неизменяемыми, они могут быть немного эффективнее списков в использовании памяти и выполнении операций.
- Методы: Списки имеют больше встроенных методов, таких как
append(),extend(),remove(), которые позволяют удобно изменять списки. Кортежи имеют намного меньше методов, так как они неизменяемы.
Списки используются для хранения упорядоченных коллекций элементов, к которым можно обращаться по индексу, изменять и расширять, тогда как кортежи используются для хранения неизменяемых последовательностей данных, например, координат точек, размеров, или возвращаемых функцией нескольких значений.
,
Множества (set) и их методы. frozenset
Множество (set) является структурой данных, которая представляет собой неупорядоченную коллекцию уникальных элементов.
Основные особенности множеств:
- Каждый элемент во множестве уникален, то есть в множестве не может быть дублирующихся элементов.
- Элементы во множестве не имеют определенного порядка, поэтому нельзя обратиться к элементу множества по индексу.
- Множества поддерживают операции над множествами, такие как объединение, пересечение, разность и другие.
Множество (set) может содержать неизменяемые типы данных (числа, булевы значения, строки, кортежи) и не может содержать изменяемые типы данных (списки, словари, множества).
Множества создаются с использованием фигурных скобок {} или функции set(). Важно: пустое множество надо создавать с помощью set() , т.к. a={} создаст словарь.
Если в set() поместить итерируемый объект с неуникальными элементами, то ошибки не будет и дублирующие друг друга элементы будут автоматически исключены, в результате мы получим множество только с уникальными элементами. Благодаря этому с помощью множеств можно легко убирать дубли из данных.
print(set([2, 34, 5, 6, 2, 34, 2, 4, 54, 2])) # {2, 34, 4, 5, 6, 54}Обращение к элементам множества по индексу или получать срезы — невозможно, т.к. это неупорядоченная коллекция.
Для определения длины множества используется функция len().
Метод .add() позволяет добавлять уникальные элементы в множество, т.е. элемент будет добавлен, если его там еще нет.
Метод update() используется для добавления нескольких элементов в множество с помощью другого множества или итерируемого объекта.
my_set= {1, 2, 3}
my_set.add(4)
my_set.add(2)
print(my_set) # {1, 2, 3, 4}
other_set= {4, 5, 6}
my_list= [7, 8, 9]
my_set.update(my_list)
my_set.update(other_set)
my_set.update((8, 9, 10, 11, 12))
my_set.update(["group", "club"])
my_set.update("cat")
print(my_set) # {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 't', 'group', 'c', 'club', 'a'}remove() используется для удаления элемента из множества. Если элемент не существует в множестве, то метод remove() генерирует ошибку KeyError.discard() используется для удаления элемента из множества в Python. Если элемент не существует в множестве, то метод discard() не генерирует ошибку, в отличие от метода remove().pop() используется для удаления и возврата (метод возвращает удаляемое значение) произвольного элемента из множества. Поскольку множества не упорядочены, конкретный элемент, который будет удален, не определен заранее. Если вызвать этот метод для пустого множества, то возникнет ошибка.clear() для множеств используется для удаления всех элементов из множества, оставляя его пустым.my_set = {1, 2, 3, 4, 5}
my_set.remove(3)
print(my_set) # {1, 2, 4, 5}
# my_set.remove(10) # Вызовет ошибку KeyError: 10
my_set.discard(1)
my_set.discard(10) # 10 нет в множестве, ошибки нет
print(my_set) # {2, 4, 5}
element = my_set.pop()
print(element) # например 2
print(my_set) # остается {4, 5}
my_set.clear()
print(my_set) # Выведет пустое множество: set()frozenset в Python — это неизменяемая версия типа данных множество (set). Основное отличие между frozenset и set заключается в том, что frozenset не может быть изменен после создания, тогда как обычное set может быть изменено путем добавления или удаления элементов.
Вот основные различия между frozenset и set:
frozensetявляется неизменяемым, тогда какsetможет быть изменено.frozensetможет быть использован в качестве ключа для словаря, в то время какsetне может быть использован в этой роли из-за своей изменяемости.
,
Операции над множествами, сравнение множеств
Пересечение двух множеств в Python представляет собой новое множество, содержащее только те элементы, которые присутствуют в обоих изначальных множествах. Это означает, что если у вас есть два множества, например, {1, 2, 3, 4} и {3, 4, 5, 6}, их пересечение будет {3, 4} , т.к. оно присутствует в обоих множествах.
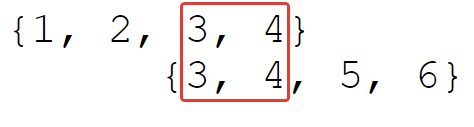
В Python для нахождения пересечения множеств используется оператор & или метод intersection(). Метод intersection_update изменяет множество, присваивая ему результат пересечения с другим(или несколькими другими) множествами.
set1= {1, 2, 3, 4}
set2= {3, 4, 5, 6}
set3= {7, 8, 9, 10}
myset=set1&set2# находим пересечение множеств
print(myset) # Выведет: {3, 4}
myset=myset&set3
print(myset) # Выведет: set()
myset=set2.intersection(set1)
print(myset) # Выведет: {3, 4}
set1.intersection_update(set2, {3, 6, 7, 8})
print(set1) # {3}Объединение двух множеств представляет собой новое множество, содержащее все уникальные элементы из обоих изначальных множеств. Это означает, что если у вас есть два множества, например, {1, 2, 3, 4} и {3, 4, 5, 6}, их объединение будет {1, 2, 3, 4, 5, 6} — так как все уникальные элементы из обоих множеств объединяются в новом множестве.
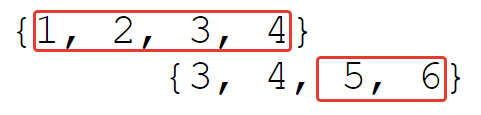
В Python для нахождения объединения множеств используется оператор | или метод union().
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
myset = set1 | set2
print(myset) # Выведет: {1, 2, 3, 4, 5, 6}
myset = set1.union(set2)
print(myset) # Выведет: {1, 2, 3, 4, 5, 6}
set1 |= set2
print(set1) # Выведет: {1, 2, 3, 4, 5, 6}Вычитание множеств представляет собой операцию, при которой из одного множества удаляются все элементы, которые присутствуют в другом множестве. Это означает, что если у вас есть два множества, например, {1, 2, 3, 4} и {3, 4, 5, 6}, результатом вычитания будет новое множество, содержащее элементы из первого множества, которые не содержатся во втором множестве.

В Python для нахождения разности множеств используется оператор - или метод difference().
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
myset = set1 - set2
print(myset) # Выведет: {1, 2}
myset = set2 - set1
print(myset) # Выведет: {5, 6}
myset = set1.difference({-1, 0, 2})
print(myset) # Выведет: {1, 3, 4}
myset -= set2
print(myset) # Выведет: {1}Симметричная разность двух множеств представляет собой новое множество, содержащее элементы, которые присутствуют только в одном из исходных множеств, но не в обоих. Другими словами, симметричная разность включает в себя элементы, которые есть в любом одном из множеств, но не в обоих одновременно.
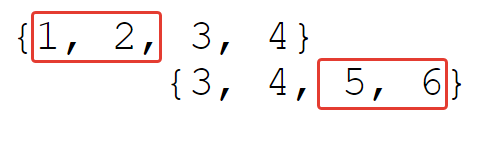
В Python для нахождения симметричной разности множеств используется оператор ^ или метод symmetric_difference().
set1 = {1, 2, 3, 4}
set2 = {3, 4, 5, 6}
myset = set1 ^ set2
print(myset) # Выведет: {1, 2, 5, 6}
myset = myset.symmetric_difference(set2)
print(myset) # Выведет: {1, 2, 3, 4}Сравнение множеств. В Python множества можно сравнивать между собой с помощью операторов сравнения для определения их отношений. Для сравнения множеств используют операторы сравнения:
==: Проверяет, содержат ли два множества одни и те же элементы. Если множества содержат одни и те же элементы, они считаются равными.!=: Проверяет, содержат ли два множества разные элементы. Если множества содержат хотя бы один различный элемент, они считаются неравными.<: Проверяет, является ли одно множество подмножеством другого. Если все элементы одного множества содержатся в другом, но оба множества не равны, то первое множество является подмножеством второго.>: Проверяет, является ли одно множество строгим подмножеством другого. Это означает, что все элементы первого множества содержатся во втором, но множества не равны.<=: Проверяет, является ли одно множество подмножеством или равным другому множеству. Если все элементы одного множества содержатся в другом, включая равенство, то первое множество является подмножеством или равным второму.>=: Проверяет, является ли одно множество строгим подмножеством или равным другому множеству. Если все элементы первого множества содержатся во втором, включая равенство, но множества не равны, то первое множество является строгим подмножеством или равным второму.
При сравнении множеств в Python порядок элементов не имеет значения, так как множества неупорядочены.
set1 = {1, 2, 3}
set2 = {3, 2, 1}
set3 = {1, 2, 4}
set4 = {1, 2}
print(set1 == set2) # Выведет: True, так как содержат одни и те же элементы
print(set1 == set4) # Выведет: False, так как содержат разные элементы
print(set1 != set3) # Выведет: True
print(set3 > set4) # Выведет: True, так как set3 содержит все элементы set4 и больше
print(set1 > set3) # Выведет: False
print(set1 <= set2) # Выведет: True,
Генераторы множеств и генераторы словарей
Генераторы множеств в Python позволяют создавать множества с использованием компактного и выразительного синтаксиса. Генераторы множеств позволяют создавать множества на основе итерации по другим итерируемым объектам или последовательностям. Создание генераторов множеств, как и словарей, очень напоминает создание ранее рассмотренные генераторы списков.
Синтаксис: {выражение for элемент in итерируемый_объект [if условие]}
# Пример генератора множества для нахождения четных чисел из диапазона:
numbers = {x for x in range(10) if x % 2 == 0}
print(numbers) # Выведет: {0, 2, 4, 6, 8}
# Генератор словаря для создания словаря, где ключ - число, значение - квадрат этого числа
squares_dict = {num: num**2 for num in range(1, 6)}
print(squares_dict) # Выведет: {1: 1, 2: 4, 3: 9, 4: 16, 5: 25},
Функции
Функции: первое знакомство, определение def и их вызов
Функция в программировании — это блок кода, который может быть вызван из других частей программы. Она может принимать аргументы, выполнять определенные действия и возвращать результат.
В Python имя функции — это идентификатор (ссылка), который используется для вызова объекта-функции. Оно должно быть уникальным в рамках своего пространства имен. Для наглядности изменим идентификатор для <built-in function print> — встроенной в Python функции, которая используется для вывода данных на консоль или другое устройство вывода.
p = print
print = "Изучаем функции"
p(print) # Изучаем функцииВ python предусмотрено множество встроенных функций — смотрите .
Но для эффективного написания программ предусмотрена возможность самим создавать функции.
Общий синтаксис функций:

Функции создаются с использованием ключевого слова def, за которым следует имя функции и круглые скобки, содержащие аргументы функции. Тело функции начинается с отступа и может содержать любой код, необходимый для выполнения определенных действий. По завершении выполнения функции может быть использован оператор return, чтобы вернуть результат функции. Если оператор return отсутствует, функция вернет None по умолчанию.
При назывании функций в Python рекомендуется использовать осмысленные и описательные имена в форме глагола, которые отражают назначение функции. Имя функции должно начинаться с буквы или знака подчеркивания и может содержать буквы, цифры и знаки подчеркивания. При использовании нескольких слов в имени функции обычно применяется стиль snake_case, где слова разделяются знаками подчеркивания. Избегайте использования зарезервированных слов и стандартных функций Python в качестве имен функций, таких как print, input, list и т. д.
def hi(name):
return f"Привет, {name}!"
print(hi("студент"))Параметр — это переменная, которая указывается в определении функции. Параметры являются частью сигнатуры функции и определяют, какие данные функция принимает при вызове.
Аргумент — это конкретное значение, которое передается функции при ее вызове. Аргументы соответствуют параметрам функции и представляют собой данные, которые функция обрабатывает.
В нашем примере name — это параметр функции hi, а «студент» — это аргумент, передаваемый при вызове функции.
Оператор вызова функции в Python — это пара круглых скобок (), которая следует за именем функции и может содержать аргументы, передаваемые функции. Например print('123') или print().
,
Оператор return / Функциональное программирование
Оператор return в Python используется внутри функций для возврата результата выполнения функции. Когда интерпретатор Python достигает оператора return, он немедленно завершает выполнение функции и возвращает указанное значение.
Оператор return может возвращать любое значение или объект, включая числа, строки, списки, кортежи, словари и другие объекты. Если оператор return отсутствует в функции, она все равно завершится, но вернет None по умолчанию.
Пример функции, которая возвращает удвоенное число:
def double_number(number):
doubled_number = number * 2
return doubled_number
print(double_number(5))В Python функция может вернуть несколько переменных, путем упаковки их в кортеж, список или словарь. При вызове функции с несколькими возвращаемыми значениями, они могут быть присвоены различным переменным.
def get_values():
return 1, 2, 3
a, b, c = get_values()
print(a, b, c)Функциональное программирование — это парадигма программирования, в которой программа строится с использованием функций как основных строительных блоков.
Ключевые принципы функционального программирования включают в себя:
- Чистота функций: функции не имеют побочных эффектов и возвращают одинаковый результат для одних и тех же аргументов.
- Неизменяемость: данные являются неизменяемыми, и любые операции над данными создают новые данные, а не модифицируют существующие.
- Рекурсия: рекурсивные функции широко используются для итерации и решения задач.
- Функции высшего порядка: функции могут принимать другие функции в качестве аргументов или возвращать их как результат.
,
Именованные аргументы. Фактические и формальные параметры
Как вы помните аргумент — это конкретное значение, которое передается функции при ее вызове, они соответствуют параметрам функции.
Аргументы бывают двух типов: позиционные и именованные.
Позиционные аргументы: Это аргументы, которые передаются функции по порядку. Порядок передачи аргументов важен, так как они связываются с параметрами функции в том же порядке.
Именованные аргументы: Это аргументы, которые передаются функции с указанием имени параметра. Порядок передачи не важен, так как каждый аргумент связывается с соответствующим именованным параметром.
def greet(name, age):
print(f"Привет, {name}! Тебе уже {age} лет.")
# используем позиционные аргументы
greet("Сергей", 50)
# используем именованные аргументы
greet(age=25, name="Анна")Напомним, что параметр — это переменная, которая указывается в определении функции. Параметры определяют, какие данные функция принимает при вызове.
При определении функции ее параметрам могут быть присвоены значения по умолчанию. Такое значение заменяется на соответствующий фактический аргумент, если он был передан при вызове функции. Однако если фактический параметр не был предоставлен, то внутри функции будет использоваться значение по умолчанию.
Параметры со значениями по умолчанию называются формальными, а обычные – фактическими. Формальные параметры не обязательно прописывать при вызове функции.
def greet(name, greeting="Привет"):
print(f"{greeting}, {name}!")
greet("Анна") # Выведет: Привет, Анна!
greet("Сергей", "Здравствуй") # Выведет: Здравствуй, Сергей!,
Функции с произвольным числом параметров *args и **kwargs
В Python параметры с произвольным числом аргументов могут быть переданы функции с помощью звёздочек (*) и двойных звёздочек (**).
Параметры со звёздочкой (*args): позволяют передавать произвольное число обычных позиционных аргументов. Аргументы передаются как кортеж.
Параметры с двойной звёздочкой (**kwargs): позволяют передавать произвольное число именованных аргументов. Аргументы передаются как словарь.
def my_function(*args):
print(type(args)) # <class 'tuple'>
for parametr in args:
print(parametr, end=" ")
my_function(1, 2, 3) # 1 2 3
def my_function(**kwargs):
print(type(kwargs)) # <class 'dict'>
for key, value in kwargs.items():
print(f"{key}: {value}", end=" ")
my_function(name="Violetta", age=30, pol="woman", city="Piter")
# name: Violetta age: 30 pol: woman city: Piter,
Операторы * и ** для упаковки и распаковки коллекций
В Python оператор * используется для распаковки итерируемых объектов, таких как списки, кортежи, множества при передаче аргументов в функцию или при создании других структур данных.
Оператор ** используется для распаковки словарей (последовательности в качестве элементов которых имеется ключ и значение).
Чтобы визуально определить, используется ли * для упаковки или распаковки, обратите внимание на контекст, в котором он используется в коде. Если * используется для передачи аргументов в функцию, это упаковка. Если * используется для извлечения элементов из итерируемого объекта, это распаковка.
my_list = [1, 2, 3]
print(*my_list) # Распаковка списка при выводе: 1 2 3
my_dict = {"a": 10, "b": 20}
print(**my_dict) # Ошибка, т.к. нет функции, принимающей именованные аргументы
def my_func(a, b):
print(a, b)
my_dict = {"a": 10, "b": 20}
my_func(**my_dict) # Распаковка словаря как именованных аргументов
def my_func(*args):
for arg in args:
print(arg)
my_func(1, 2, 3) # Упаковка аргументов при вызове функции
my_tuple = (1, 2, 3)
packed_tuple = (*my_tuple,) # Упаковка в кортеж
print(packed_tuple) # Вывод: (1, 2, 3),
Рекурсивные функции
Рекурсивные функции — это функции, которые вызывают сами себя в своем теле. Они часто используются для решения задач, которые могут быть разбиты на более мелкие подзадачи. Рекурсивные функции могут быть мощным инструментом, но их следует использовать осторожно, чтобы избежать бесконечной рекурсии.
Пример рекурсивной функции, вычисляющей факториал числа. Факториал числа n — это произведение всех натуральных чисел от 1 до n включительно. Обозначается переменной n! (произносится: «эн факториал»). Функция в примере ниже вычисляет факториал числа n путем рекурсивного умножения числа n на факториал предыдущего числа (n-1).
def factorial(n):
if n == 0:
return 1
else:
return n * factorial(n - 1)
print(factorial(9)) # 362880Рекурсивные функции вызывают самих себя либо прямо, либо косвенно с целью организации цикла. Это сложная тема и она редко встречается, т.к. Python имеет более простые
циклические структуры. Рекурсия может быть альтернативой несложным циклам и итерациям, но более сложной и не всегда эффективной.
вот пример функции вычисления суммы элементов списка
def mysum(L):
if not L:
return 0
else:
return L[0] + mysum(L[1:]) # Рекурсивный вызов самой себя
print(mysum([1, 2, 3, 4, 5])) # сумма элементов списка = 15[1, 2, 3, 4, 5]
[2, 3, 4, 5]
[3, 4, 5]
[4, 5]
[5]
[]
15
Суммируемый список на каждом уровне рекурсии становится все меньше, пока окончательно не опустеет. Сумма при этом вычисляется при раскручивании рекурсивных вызовов по возврату.
Также обратите внимание, что если вы хотите использовать результат рекурсивного вызова, вам обычно нужно включить его в выражение return, чтобы передать его вверх по цепочке вызовов.
P.S. задачи в этой теме курса реально сложные, это как некая подготовка к соревнованиям по программированию. Лично я решения 2х задач был вынужден просто искать и пытался вникнуть в суть их решения 🙁
,
Анонимные (lambda) функции
Лямбда-функции, также известные как анонимные функции, представляют собой небольшие функции без имени. Лямбда-функции полезны, когда вам нужна простая функция на короткий период времени, и вы не хотите определять полноценную функцию с использованием ключевого слова def.
Синтаксис: лямбда-функции определяются с использованием ключевого слова lambda, за которым следуют параметры и двоеточие, затем выражение для вычисления. Простые примеры:
# Лямбда-функция, которая складывает два числа
add = lambda x, y: x + y print(add(3, 4)) # Вывод: 7
# Лямбда-функция для проверки на четность числа
is_even = lambda x: x % 2 == 0
print(is_even(5)) # Вывод: FalseЛямбда-функции может быть записана как элемент любой конструкции Python.
Лямбда-функции ограничены одним выражением и не могут содержать множественные строки кода.
Нельзя в lambda функциях использовать оператор присваивания (например а=7).
Лямбда-функции целесообразно использовать для небольших и простых операций. Также они часто используются вместе с функциями более высокого порядка, такими как map(), filter(), sorted() и другими. Лямбда-функции можно использовать в качестве аргумента, передаваемого иной функции.
,
Области видимости переменных. Ключевые слова global и nonlocal. Функции locals() и globals().
Область видимости переменной определяет код программы, в котором переменная может быть использована или найдена. Область видимости определяет, где переменная может быть доступна для чтения или записи.
В Python существуют несколько уровней области видимости переменных:
- Локальная область видимости, Локальное пространство имен (local): Переменные, определенные внутри функции, являются локальными для этой функции и не видны за ее пределами. Т.е. имя переменной определено внутри блока кода функции и область действия такой переменной расширяется на любые блоки кода, входящие в этот блок, если только содержащий блок не вводит другую привязку для имени (nonlocal или global).
- Глобальная область видимости (global): Переменные, объявленные вне всех функций или внутри функций с ключевым словом
global, являются глобальными и доступны из любого места программы. Глобальную переменную нельзя напрямую изменить внутри функции, если только эта переменная не определена с помощью инструкцииglobal, внутри этой функции.
global — означает, что перечисленные в инструкции переменные должны интерпретироваться как глобальные. Имена, перечисленные в инструкции global, не должны использоваться в блоке кода, предшествующем global. Имена, перечисленные в инструкции global, не должны быть определены как аргументы функции или использоваться в целевом элементе item управления циклом for item in …. global используют, когда это действительно необходимо, при этом оператор global в блоке функции правильней указывать в качестве первой инструкции.
Инструкция nonlocal определяет имена ранее определенных переменных в ближайшей области видимости, исключая глобальную. Имена должны ссылаться на ранее существовавшие переменные в окружающей области. Переменную, определенную в родительской функций, нельзя изменить внутри вложенной функции, если только она не определена с помощью оператора nonlocal внутри вложенной функции.
nonlocal можно писать только в том пространстве имен, которое ссылается на другое внешнее пространство имен, которое также должно быть локальным.
global_var = 777
def outer_function():
global global_var
global_var = "global variable"
local_var = "333"
def inner_function():
nonlocal local_var
local_var = "local variable"
inner_function()
print(local_var) # выведет "local variable", а не 333
outer_function()
print(global_var) # выведет "global variable", а не 777Для отладки программы, чтобы узнать значения переменных, удобно использовать функции locals() и globals() .
locals() — это встроенная функция в Python, которая возвращает словарь, содержащий локальные переменные в текущей локальной области видимости. Область видимости определяется тем кодом, который был выполнен до вызова locals(). Эта функция полезна для доступа к локальным переменным внутри функции или блока кода. Если функция вызвана внутри другой функции, то она возвращает также свободные (объявленные вне функции, но используемые внутри неё) переменные.
globals() — это встроенная функция в Python, которая возвращает словарь, содержащий все глобальные переменные в текущей области видимости. Эта функция полезна для доступа к глобальным переменным внутри модуля или скрипта.
Обратите внимание, что на уровне модуля, функции locals() и globals() возвращают один и тот же словарь.
Нужно быть осторожным при использовании locals() и globals() , так как изменение возвращаемого словаря может привести к непредсказуемому поведению программы. Изменять локальные переменные в Python используя возвращаемый функцией словарь не стоит.
и , и .
,
Замыкания в Python
Замыкание (closure) в Python — это функция, которая запоминает значения из внешней области видимости, даже если эта область видимости уже не существует. Замыкание функций создается путем определения внутренней функции внутри внешней функции и использования переменных из внешней функции внутри вложенной функции. При этом вложенная функция должна использовать эти внешние переменные. Когда внутренняя функция использует переменные из внешней функции, Python автоматически создает замыкание, которое позволяет внутренней функции сохранять доступ к значениям этих переменных даже после завершения работы внешней функции.
def vneshfunc(x):
def vnutrfunc(y):
return x + y
return vnutrfunc
q = vneshfunc(10)
result = q(5)
print(result) # выведет 15В этом примере vneshfun принимает аргумент x и возвращает внутреннюю функцию vnutrfunc. Когда мы вызываем vneshfun(10)vnutrfunc, которая запоминает значение x (равное 10). Затем мы сохраняем эту возвращенную функцию в переменную result и вызываем ее с аргументом 5, что приводит к возвращению результата 10 + 5, то есть 15. В данном примере внутренняя функция vnutrfunc создает замыкание, сохраняя значение x, которое было передано во внешнюю функцию vneshfun.
Для создания замыкания в Python важным шагом является возвращение внутренней функции из внешней функции ( в нашем случае с помощью return vnutrfunc). Это позволяет сохранить доступ к внешним переменным внешней функции для внутренней функции. Когда внешняя функция возвращает вложенную функцию, возвращаемая функция сохраняет доступ к переменным и состоянию внешней функции на момент создания замыкания. Это позволяет внутренней функции использовать эти переменные даже после завершения работы внешней функции.
,
Декораторы функций
Декораторы функций в Python — это специальный синтаксический сахар, который позволяет изменить поведение функции без изменения ее кода. Декораторы обычно используются для добавления функциональности к существующей функции. (Синтаксический сахар — это синтаксические возможности, применение которых не влияет на поведение программы, но делает использование языка более удобным для человека).
def my_decorator(func):
def wrapper():
print("Что-то происходит до вызова функции.")
func()
print("Что-то происходит после вызова функции.")
return wrapper
@my_decorator
def say_hello():
print("ПРИВЕТ!")
say_hello()В этом примере my_decorator — это декоратор, который добавляет вывод сообщений перед и после вызова функции say_hello. При использовании @my_decorator перед определением функции say_hello, функция say_hello будет автоматически обернута в my_decorator.
Ниже приведен универсальный шаблон для декораторов от одного из слушателей курса:
def decorator(func): # Сюда передаём функцию которую нужно декорировать
def wrapper(*args, **kwargs): # Сюда передаём аргументы декорированной функции
print(f'{func.__name__} started') # декорирующие действия 1
result = func(*args, **kwargs) # *args -чтобы работать с разным кол-вом аргументов
print(f'{func.__name__} finished') # декорирующие действия 2
return result # возвращаем результат
return wrapper # передаём ссылку на вложенную функцию
@decorator # сахар для вызова декоратора (навешиваем декоратор)
def summ(a, b): # функция которую нужно декорировать в этот момент: summ = wrapper
return a + b
print(summ(2, 3)),
Декораторы с параметрами. Сохранение свойств декорируемых функций
Декораторы с параметрами позволяют передавать аргументы в декораторную функцию, что делает их более гибкими. Для создания декоратора с параметрами, вы можете определить функцию, которая возвращает сам декоратор. Эта функция может принимать параметры и возвращать сам декоратор, который затем применяется к целевой функции или методу.
def my_decorator_with_params(param1, param2):
def decorator(func):
def wrapper(*args, **kwargs):
print(f"Параметры: {param1}, {param2}")
result = func(*args, **kwargs)
return result
return wrapper
return decorator
@my_decorator_with_params("параметр1", "параметр2")
def my_function():
print("Внутри функции")
my_function()my_decorator_with_params — это функция, которая возвращает декоратор decorator, принимающий параметры param1 и param2. Этот декоратор применяется к функции my_function, и при вызове my_function выводится сообщение с переданными параметрами, а затем выполняется тело функции.
,
Модули и пакеты. Работа с файлами
Импорт стандартных модулей. Команды import и from
Модули в Python — это файлы, содержащие Python код. Пакеты — это директории, содержащие один или более модулей, а также файл __init__.py. Модули позволяют организовывать код для удобного повторного использования, а пакеты позволяют организовывать модули в логические иерархии.
Стандартные модули в Python — это модули, встроенные в язык, которые предоставляют широкий спектр функциональности, включая работу с файлами, сетевое взаимодействие, математические операции и многое другое. Эти модули доступны «из коробки» при установке Python и не требуют дополнительной установки.
Полный стандартной библиотеки — в официальной документации . Помимо стандартной библиотеки, существует коллекция из сотен тысяч компонентов, доступных в .
Модуль — математические функции языка Python.
Модуль — функции для генерации случайных чисел.
Импортирование модулей в Python позволяет использовать функции, классы и другие объекты, определенные в этих модулях, в вашем коде. Это удобно для организации кода, повторного использования кода, и поддержания его чистоты и структурированности. Для импортирования модулей в Python используется ключевое слово import. Рекомендуется помещать все инструкции import в начало файла, а каждый модуль импортировать отдельной строчкой.
Основной синтаксис для импортирования модулей: import module_name .
Инструкция import в Python фактически создает ссылку на модуль и вы можете обращаться к его содержимому, используя синтаксис module_name.object_name, где object_name может быть функцией, классом или переменной из импортированного модуля. Через эту ссылку вы получаете доступ к глобальным переменным и другим объектам, определенным в импортированном модуле.
import math
print(math.sqrt(16)) # выведет квадратный корень из 16, используя функцию sqrt() из модуля math.Вы можете импортировать модуль под другим именем, используя конструкцию import <module> as <name>, тем самым создавая псевдонимы для импортируемых модулей. Это делают для сокращения набираемого кода и для удобства использования. Для этого используется ключевое слово as.
import math as m
# math был импортирован с псевдонимом m, и мы вызываем функцию sqrt() через псевдоним m
print(m.sqrt(16)) # выведет квадратный корень из 16, используя функцию sqrt() из модуля math.Выборочный импорт в Python позволяет импортировать только определенные объекты из модуля, вместо импорта всего модуля целиком. Для этого используется следующий синтаксис: from module_name import object_name1, object_name2.
После выполнения этой инструкции на имена object_name1object_name2 объектов модуля module_name можно ссылаться без префикса module_name.
from math import pi, sqrt
print(sqrt(16)) # выведет квадратный корень из 16, используя функцию sqrt() из модуля math
print(pi) # выведет константу pi из модуля mathТакже возможно импортировать из модуля вообще всё с помощью конструкции from <module> import *. В определенной степени это удобно, особенно при изучении модуля, но на практике из-за высоких шансов конфликта имен такой импорт делать не рекомендуется!
, и
,
Импорт собственных модулей
Для импорта собственных модулей, вы должны удостовериться, что файл вашего модуля находится в том же каталоге или в пути, доступном для поиска модулей интерпретатором Python. Затем вы можете импортировать свой модуль так же, как и встроенные модули, с использованием инструкции import.
Модуль sys в Python предоставляет доступ к некоторым переменным и функциям, связанным с интерпретатором Python и операционной системой. Одной из переменных, предоставляемых модулем sys, является sys.path.
— это список строк, представляющих каталоги, в которых интерпретатор Python ищет модули при импортировании. Первый элемент списка обычно содержит путь к текущему рабочему каталогу, а затем следуют другие каталоги, включая системные каталоги Python.
Вы можете изменить sys.path, чтобы добавить пути к каталогам, где находятся ваши собственные модули, чтобы интерпретатор Python мог найти их при импортировании.
import sys
sys.path.append('/путь/к/вашему/модулю')Однако обычно так не делают и просто добавляют имена подкаталогов через точку. Например import folder.mymodule. Это выражение означает, что вы импортируете модуль mymodule из пакета (каталога) folder. При этом Python будет искать модуль mymodule внутри каталога (пакета) folder.
Если в модуле нужно прописать код, выполняемый только при непосредственном запуске модуля, то его следует if __name__ == "__main__": .Эта конструкция используется для определения, запущен ли скрипт напрямую из командной строки или он был импортирован как модуль в другой скрипт. Когда Python выполняет скрипт, он устанавливает значение __name__ в "__main__" для текущего скрипта. Поэтому конструкция if __name__ == "__main__": позволяет выполнить определенные действия только в том случае, если скрипт запущен напрямую, а не импортирован как модуль другим скриптом.
,
Установка сторонних модулей (pip install). Пакетная установка
Для многочисленных сторонних модулей создан единый каталог (репозиторий) в виде отдельного сайта с кратким описанием каждого модуля —
Для установки пакетов из Python Package Index (PyPI) или из других источников используется команда pip install. Когда вы запускаете pip install package_name, pip автоматически загружает указанный пакет и его зависимости, если они есть, и устанавливает их в ваше виртуальное окружение Python.
Например для установки стороннего пакета requests используется следующая команда в терминале: pip install requests.
Для отслеживания уже установленных пакетов в вашем виртуальном окружении используется команда pip list , которая выводит список всех установленных пакетов вместе с их версиями.
Пакетная установка внешних модулей в Python означает установку нескольких сторонних модулей одновременно. Это обычно делается с помощью файла requirements.txt, в котором перечислены все необходимые модули и их версии. После создания файла requirements.txt, вы можете установить все перечисленные модули одной командой с использованием pip: pip install -r requirements.txt
Этот файл часто используется для переноса проекта с одного компьютера на другой. Его можно создать как вручную, так и с помощью команды: pip freeze > requirements.txt, после запуска которой в рабочем каталоге проекта появится текстовый файл requirements.txt с набором всех установленных модулей для текущего интерпретатора.
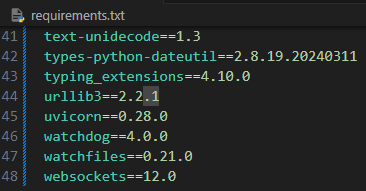
,
Пакеты (package) в Python. Вложенные пакеты
В чем разница между модулем и пакетом в Python :
Модуль: Модуль — это файл с расширением .py, который содержит код на Python. Он может содержать переменные, функции, классы и другие объекты. Модуль имеет свое уникальное имя, которое определяется именем файла без расширения.
Пакет: Пакет — это специальная директория, которая содержит модули или другие пакеты. Пакеты используются для организации и структурирования кода в Python. Пакеты обычно содержат файл __init__.py, который указывает интерпретатору Python, что директория является пакетом.
Пакеты обычно используются для организации связанных модулей вместе, в то время как модуль представляет собой отдельный файл с кодом.
Пакеты позволяют организовывать модули Python в логически связанные группы, облегчая управление и структурирование кода. Когда вы импортируете модуль из пакета, вы используете точечную нотацию, например: import package_name.module_name , где package_name — это имя вашего пакета, а module_name — имя модуля внутри этого пакета. Это абсолютное импортирование по их полному имени или пути в файловой системе проекта. Относительное импортирование позволяет импортировать модули или пакеты с использованием относительного пути внутри структуры проекта. Есть два вида относительного импортирования: 1) Относительное импортирование модуля: для импорта модуля из того же пакета используется точечная нотация. Например, если у нас есть пакет my_package и модуль my_module в этом пакете, чтобы импортировать my_module из другого модуля внутри того же пакета, мы можем использовать from . import my_module. 2) Относительное импортирование пакета: для импорта пакета из родительского пакета также используется точечная нотация. Например, если у нас есть пакет parent_package и внутри него пакет child_package, чтобы импортировать parent_package из child_package, мы можем использовать from .. import parent_package. Такое импортирование используют в больших проектах. import работает только с абсолютными путями.
Атрибут __all__ в Python используется для определения списка имен, которые будут импортированы при использовании конструкции from module import *. Когда модуль содержит атрибут __all__, только имена, перечисленные в этом атрибуте, будут импортированы при использовании from module import *. Это позволяет явно контролировать, какие имена будут доступны из модуля при использовании звездочки. Если атрибут __all__ отсутствует, то при использовании from module import * будут импортированы все имена, которые не начинаются с символа подчеркивания _. Т.е. использование __all__ позволяет более точно управлять экспортируемыми именами из модуля при использовании звездочки. Атрибут __all__ часто, но не обязательно прописывается в файле __init__.py, атрибут __all__ обычно прописывается непосредственно в файле модуля, в котором определяются имена, которые должны быть доступны при использовании from module import *.
В Python все пакеты являются модулями, так как они представлены файлами или директориями и обладают атрибутами, такими как __name__. Однако не все модули могут быть пакетами. Модуль, который является пакетом, должен содержать файл __init__.py и может содержать другие модули или пакеты внутри себя. Обычные модули в Python не обязаны иметь этот файл и не могут содержать другие модули или пакеты.
В Python термин «пакет» обычно относится к директории, которая содержит модули Python. Эти директории обычно содержат файл __init__.py, который определяет, что директория должна рассматриваться как пакет. Если файл с именем __init__.py присутствует в каталоге пакета, то он вызывается при импорте пакета или модуля в пакете.
__init__.py может устанавливать или изменять атрибут пакета __path__. Атрибут __path__ содержит список строк, представляющих путь к директории, которая содержит подмодули пакета. Когда интерпретатор Python обрабатывает импорт модуля из пакета, он проверяет атрибут __path__ для определения местоположения подмодулей пакета.
Если у модуля есть атрибут __path__, это означает, что это модуль является частью пакета.
, и
,
Функция open. Чтение данных из файла
Функция open() в Python используется для открытия файлов в различных режимах (например, для чтения, записи, добавления и т. д.). Она возвращает объект файлового дескриптора, который может быть использован для чтения или записи данных в файл.
Синтаксис функции open() : open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None), значение параметров:
file: Имя файла или путь к файлу, который нужно открыть.mode(опционально): Режим открытия файла. По умолчанию установлен в режим чтения'r'.'r': Чтение. Открывает файл для чтения. Если файл не существует, возникает ошибка.'w': Запись. Открывает файл для записи. Если файл существует, его содержимое удаляется. Если файл не существует, создается новый файл для записи.'a': Добавление. Открывает файл для добавления (дописывания) в конец файла. Если файл не существует, создается новый файл для записи.'r+': Чтение и запись. Открывает файл для чтения и записи. Файл не обрезается, но указатель файла устанавливается в начало файла.'w+': Запись и чтение. Открывает файл для чтения и записи. Если файл существует, его содержимое удаляется, и создается новый файл для записи и чтения."a+": Открыть файл для чтения и добавления (дополнения).- Кроме того, можно указывать дополнительные флаги, например
"b"для работы с файлами в бинарном режиме (например,"rb","wb","ab", и т.д.).
buffering(опционально): Управляет буферизацией данных. По умолчанию-1— использовать системное значение буферизации.encoding(опционально): Используемая кодировка для чтения и записи файла.'utf-8': Это одна из самых распространенных кодировок, поддерживающая большинство символов Unicode.'ascii': Стандартная кодировка ASCII, ограниченная 7-битным набором символов.'cp1251': Кодировка Windows-1251 для символов кириллицы.
errors(опционально): Способ обработки ошибок кодировки.newline(опционально): Управляет символами новой строки. По умолчаниюNone.closefd(опционально): Еслиclosefd=True, то файловый дескриптор будет закрыт при закрытии файла. По умолчаниюTrue.opener(опционально): Функция, которая будет использоваться для открытия файла.
Функция open() возвращает объект файлового дескриптора, который может быть использован для работы с файлом (чтение, запись, добавление и т. д.). После завершения работы с файлом, его необходимо закрыть с помощью метода close().
Метод read() в Python используется для чтения содержимого файла. Когда вызывается метод read(), он читает и возвращает определенное количество символов из файла, начиная с текущей позиции указателя файла. Если не указан аргумент, метод read() читает весь файл до конца. Обратите внимание, что при использовании метода read(), указатель файла перемещается в конец файла после чтения, поэтому при последующих операциях чтения вы начнете читать с конца файла.
with open('example.txt', 'r') as file:
content = file.read()
print(content)Файловая позиция — это конкретное место в файле, на которое указывает указатель файла. Указатель файла представляет собой позицию, на которой будет осуществляться следующая операция чтения или записи в файле. При открытии файла в режиме чтения или записи, указатель файла обычно устанавливается в начало файла. После каждой операции чтения или записи, указатель перемещается на количество байт, прочитанных или записанных. Управление файловой позицией позволяет читать и записывать данные в файле в нужном порядке и избегать дублирования информации. Если необходимо изменить позицию указателя файла, можно использовать методы, такие как seek() в Python.
Метод seek() используется для перемещения указателя файла в определенную позицию. Этот метод позволяет управлять файловой позицией, то есть указать, на какой байт в файле нужно установить указатель файла. Синтаксис метода: file.seek(offset, whence), где offset— число, указывающее на количество байтов, на которое нужно переместить указатель. Положительные значения сдвигают указатель вперед, а отрицательные — назад; whence (необязательный аргумент) определяет, относительно чего будет производиться смещение. Возможные значения: 0 (по умолчанию) — смещение от начала файла, 1 — смещение от текущей позиции указателя, 2 — смещение от конца файла.
Метод tell() используется для получения текущей позиции указателя в файле. Когда вызывается метод tell(), он возвращает текущее смещение указателя от начала файла в байтах. Метод полезен, когда вам нужно знать текущую позицию указателя в файле, например, для отслеживания прогресса чтения файла или для перемещения указателя и последующего чтения с определенной позиции.
Метод readline() используется для чтения одной строки из файла, начиная с текущей позиции указателя файла и до символа перевода строки \n. Когда вызывается метод readline(), он возвращает строку, содержащую символы до символа новой строки или до конца файла. Если вызывать метод readline() несколько раз, он будет читать следующие строки из файла по одной строке за раз, каждый раз, когда вызывается. Если вам нужно прочитать определенное количество символов, а не целую строку, вы можете передать количество символов в качестве аргумента методу readline(), например: line = file.readline(10) прочтет первые 10 символов из текущей строки. Метод readline() удобен для построчного чтения файлов, особенно когда вам нужно обрабатывать файлы построчно.
with open('example.txt', 'r') as file:
line = file.readline()
print(line)# После выполнения будет выведена первая строка файлаМетод readlines() используется для чтения всех строк из файла и возвращения их в виде списка строк. При вызове метода readlines(), он читает все строки из файла, начиная с текущей позиции указателя файла, и возвращает список строк, каждая строка представлена как отдельный элемент списка. Обратите внимание, что для очень больших файлов может возникнуть ошибка из-за нехватки памяти для хранения полученного списка строк.
Метод close() в Python используется для закрытия открытого файла после завершения работы с ним. При вызове метода close(), все буферизованные данные записываются на диск, и файл освобождается, что позволяет другим программам или процессам получить доступ к этому файлу. Не закрывание файла может привести к потере данных или недоступности файла для других программ.
Хорошей практикой является использование менеджера контекста with, который автоматически закрывает файл после завершения блока кода. Пример использования with для открытия и автоматического закрытия файла:
with open('example.txt', 'r') as file:
# работа с файлом внутри блока withПри использовании with, файл будет автоматически закрыт после завершения блока with, даже если возникнут ошибки в процессе работы с файлом.
, , и
,
Исключение FileNotFoundError и менеджер контекста (with) для файлов
FileNotFoundError — это исключение в Python, которое возникает, когда программа пытается открыть файл, который не существует. Это может произойти, например, при попытке чтения или записи в файл, который был удален или перемещен.
При работе с файлами необходимо обрабатывать исключение FileNotFoundError, чтобы программа продолжала работать в любом случае. Для этого используют конструкции для обработки исключения try / except / finally , здесь:
try: В этом блоке помещается код, который может вызвать исключение.except: В этом блоке указывается, как обрабатывать исключение, которое может возникнуть в блокеtry.finally: Этот блок выполняется всегда, независимо от того, возникло исключение или нет. Здесь обычно размещают код, который должен быть выполнен в любом случае, например, закрытие файла или освобождение ресурсов.
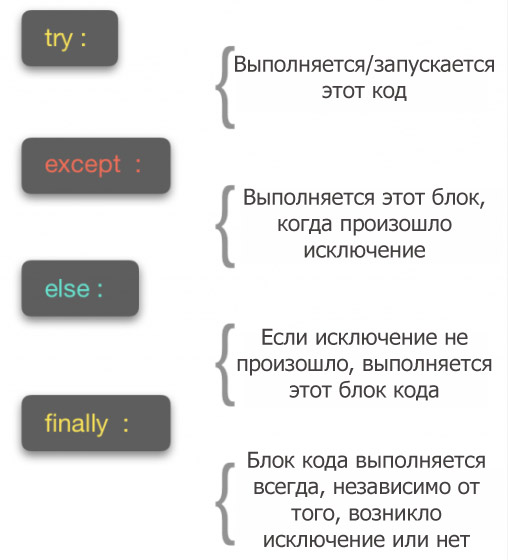
file = None
try:
file = open("nonexistent_file.txt", encoding="utf-8")
print(file.read())
except FileNotFoundError:
print("Файл не найден!")
finally:
if file is not None:
file.close()
print(file.closed)В приведенном примере код пытается открыть файл "nonexistent_file.txt" для чтения с указанием кодировки "utf-8". Если файл не существует, будет выведено сообщение "Файл не найден!". В блоке finally проверяется, был ли файл успешно открыт. Если так (переменная file не равна None), то файл закрывается с помощью file.close(), и затем выводится значение атрибута file.closed, который показывает, закрыт ли файл.
file.closed — это атрибут объекта файла в Python, который указывает на то, закрыт ли файл. Если значение file.closed равно True, то файл закрыт. Если значение file.closed равно False, то файл открыт. Рекомендуется всегда закрывать файл после завершения работы с ним, чтобы избежать утечек ресурсов.
Менеджер контекста в Python — это объект, который реализует методы __enter__() и __exit__(). Он используется с ключевым словом with для определения блока кода, который требует установки и освобождения ресурсов, например, открытия и закрытия файлов, работы с сетевыми соединениями и т. д.
Работа с менеджером контекста в Python позволяет автоматически выполнять определенные операции до и после выполнения определенного блока кода. Это особенно полезно при работе с ресурсами, такими как файлы или сетевые соединения, где важно гарантировать, что ресурсы будут корректно освобождены после использования.
Для работы с менеджером контекста используется ключевое слово with.
Пример работы с файлом с использованием менеджера контекста:
with open("example.txt", "r") as file:
content = file.read()
# Здесь файл автоматически закроется после выхода из блока `with`При использовании менеджера контекста не нужно явно вызывать метод file.close(), так как он будет вызван автоматически после выхода из блока with, даже в случае возникновения исключения.
, и
,
Запись данных в файл в текстовом и бинарном режимах
Для записи данных в файл в текстовом режиме используется функция open() с режимом записи "w" (write) или добавления "a" (append). После открытия файла для записи, можно использовать метод write() для записи данных в файл.
# Открываем файл для записи (если файл не существует, он будет создан)
with open("output.txt", "w", encoding="utf-8") as file:
file.write("Привет, мир!\n")
file.write("Это пример записи данных в файл.\n")В этом примере мы открываем файл "output.txt" для записи с режимом "w" и записываем две строки в файл с помощью метода write(). После завершения блока with файл будет автоматически закрыт.
При использовании режима "a" данные будут добавлены в конец файла без удаления существующего содержимого:
# Открываем файл для добавления данных в конец файла
with open("output.txt", "a", encoding="utf-8") as file:
file.write("Это новая строка, добавленная в конец файла.\n")Если же мы хотим и записывать и считывать информацию, то можно воспользоваться режимом w+ или a+. Основное различие между ними заключается в том, что w+ удаляет существующее содержимое файла и начинает запись с начала файла, в то время как a+ добавляет данные в конец файла, сохраняя существующее содержимое.
Чтение и запись в бинарном режиме в Python позволяет работать с данными в их бинарном представлении. Для этого используются режимы доступа к файлу, такие как "rb" для чтения в бинарном режиме и "wb" для записи в бинарном режиме.
Бинарный режим используется для работы с файлами в двоичном формате, где данные представлены в виде последовательности байтов. Когда файл открывается в бинарном режиме, это означает, что данные в файле будут интерпретироваться как последовательность байтов, а не текстовых символов. При работе в бинарном режиме, данные не подвергаются автоматической кодировке или декодировке, и они сохраняются точно так, как они записаны. Это полезно, например, при работе с изображениями, аудиофайлами, видеофайлами или другими типами файлов, где важна точная последовательность байтов.
Модуль pickle в Python предоставляет возможность сериализации (преобразования объектов Python в поток байтов) и десериализации (восстановления объектов из байтового потока). Он часто используется для сохранения сложных структур данных Python в файлах. Модуль pickle может преобразовать сложный объект в поток байтов и может преобразовать поток байтов в объект с такой же внутренней структурой.
Использование модуля pickle зависит от конкретной ситуации. Вот несколько ситуаций, когда его использование может быть полезным: сохранение и загрузка сложных объектов Python; кеширование результатов вычислений; обмен данными между Python-программами. Однако, следует учитывать некоторые ограничения модуля pickle, такие как безопасность (неконтролируемая десериализация может представлять угрозу безопасности) и несовместимость между разными версиями Python.
Если вам нужно сохранить и загрузить простые данные, такие как строки или числа, использование модуля pickle может быть избыточным, и вместо этого можно использовать стандартные методы чтения и записи файлов в текстовом или бинарном режиме.
,
Генераторы. Некоторые полезные функции
Выражения генераторы
Выражения-генераторы (generator expressions) в Python — это компактный способ создания генераторов. Они похожи на генераторы списков, но используют круглые скобки вместо квадратных скобок. Выражения-генераторы позволяют создавать генераторы без явного определения функции.
gen = (x**2 for x in range(5))
print(list(gen)) # Вывод: [0, 1, 4, 9, 16]
print(gen) # <generator object <genexpr> at 0x0000027C04598380>
print(type(gen)) # <class 'generator'>В приведенном примере выражение-генератор создает генератор для генерации квадратов чисел от 0 до 4. Класс <class 'generator'> представляет собой тип объекта-генератора. Объекты этого класса создаются при вызове функций, содержащих ключевое слово yield или при использовании выражений-генераторов.
Объекты-генераторы поддерживают протокол итерации, что означает, что они могут быть использованы в циклах for, генераторных выражениях и других конструкциях, ожидающих последовательности значений. Класс <class 'generator'> предоставляет методы для управления выполнением генератора, такие как send(), throw(), close(), но обычно эти методы используются редко.
Генераторы особенно полезны при работе с большими наборами данных, так как они не хранят все значения в памяти сразу, а генерируют их по требованию, что экономит ресурсы.
Так как генератор также является и итератором, то его значения можно перебирать с помощью функции next(). Генераторы можно перебрать только один раз. После полного прохода по всем значениям в генераторе и достижения его конца, генератор исчерпывается, и повторный проход по нему не даст новых значений. Если нужно использовать значения из генератора снова, то нужно создать новый экземпляр генератора. Именно поэтому функция len() не работает напрямую с генераторами, т.к. они генерируют значения по требованию, не сохраняя их все сразу в памяти. По этой же причине нельзя обращаться к элементам генератора по индексу. А если вам необходимо узнать длину генератора, то сначала надо преобразовать его в список или другую коллекцию.
и
,
Функция-генератор. Оператор yield
Функция-генератор в Python — это функция, которая возвращает итератор. Итератор представляет собой объект, который может быть использован для итерации по элементам некоторого набора данных.
Функция-генератор: 1) Cодержит одно или несколько выражений yield; 2) При вызове возвращает объект типа generator, но не начнет выполнение; 3) Методы __iter__() и __next__() реализуются автоматически; 4) После каждого вызова функция приостанавливается, а управление передается вызывающей стороне; 5) Локальные переменные и их состояния запоминаются между последовательными вызовами; 5) Когда вычисления заканчиваются по какому то условию, автоматически вызывается StopIteration.
Оператор yield в Python используется внутри функции для создания функции-генератора. Когда функция содержит оператор yield, она становится функцией-генератором.
Когда функция-генератор вызывается, она не выполняется сразу как обычная функция. Вместо этого она возвращает объект-генератор, который можно использовать для управления выполнением функции. Когда вызывается метод next() на объекте-генераторе, выполнение функции-генератора продолжается до тех пор, пока не встретится оператор yield.
Когда оператор yield достигается, функция возвращает значение, указанное после ключевого слова yield, но остается во «временной паузе». Значение возвращается как результат вызова метода next(), а при следующем вызове next() выполнение функции продолжается с того места, где был оператор yield.
Вы можете использовать оператор yield несколько раз в функции-генераторе, чтобы возвращать последовательность значений по мере необходимости.
def even_numbers():
n = 0
while n < 10:
yield n
n += 2
gen = even_numbers() # Создание объекта-генератора
print(next(gen))
print(next(gen))
print(next(gen))
print(next(gen))в этом примере функция-генератор генерирует все четные числа от 0 до 10. Обратите внимание, что если мы будем обращаться с помощью print(next(even_numbers())) , то каждый раз будет создаваться новый объект-генератор, и выполнение функции-генератора начинается сначала. Это означает, что при каждом вызове next() будет возвращаться первый элемент последовательности, так как начало выполнения функции-генератора сбрасывается. Если вы хотите получить доступ к последовательным элементам функции-генератора, то надо сохранить объект-генератора в переменной и затем использовать эту переменную для вызова next(). Поэтому использование print(next(even_numbers())) будет работать, но не будет продолжать последовательность элементов из предыдущего вызова.
Также можно создать список (кортеж, множество), который заполнится элементами, сгенерированными функцией-генератором even_numbers(), например так sp = list(even_numbers()) .
С помощью функции-генератора можно сразу в одном месте написать код для решения достаточно сложных задач, что трудновыполнимо сделать с помощью обычного генератора.
,
Функция map
map() — это встроенная функция Python, которая применяет указанную в ней функцию к каждому элементу итерируемого объекта (например, списку) и возвращает объект итератора с результатами.
Синтаксис map(function, iterable), где function — ссылка на функцию, которую нужно применить к каждому элементу итерируемого объекта (без круглых скобок); iterable — итерируемый объект, на который нужно применить функцию.
Например можно числа из списка возвести в квадрат с помощью map() и функцией lambda:
squared_numbers = map(lambda x: x**2, [1, 2, 3, 4, 5])
print(type(squared_numbers)) # <class 'map'>
print(list(squared_numbers)) # [1, 4, 9, 16, 25]<class 'map'> — это тип данных в Python, который представляет собой результат применения функции map() к итерируемому объекту. <class 'map'> является итератором. Итератор — это объект, который позволяет поочередно перебирать элементы коллекции, не храня все элементы в памяти сразу. Чтобы увидеть результаты применения map() можно преобразовать его в другую структуру данных, такую как список, с помощью функции list().
Функция map() используется для удобства, чтобы не создавать генератор в классическом виде, при этом внутренний цикл функции map() более эффективный, чем обычный цикл for в Python.
,
Функция filter для отбора значений итерируемых объектов
filter() — это встроенная функция Python, которая фильтрует элементы итерируемого объекта (например, списка) согласно заданному условию, представленному в виде функции.
Синтаксис filter(function, iterable), где function — функция, которая определяет условие фильтрации элементов; iterable — итерируемый объект, который нужно отфильтровать.
Функция filter() возвращает итератор с элементами, для которых функция function возвращает True, если она для элемента итерируемого объекта возвращает False , то этот элемент последовательности iterable не будет включен в результирующий набор.
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(even_numbers) # [2, 4, 6, 8]filter() вместе с функцией lambda в приведенном примере отфильтровываются только четные числа.,
Функция zip. Примеры использования
Функция zip() в Python используется для объединения нескольких последовательностей в одну последовательность кортежей, где каждый кортеж содержит элементы из соответствующих последовательностей.
Синтаксис: zip(sequence1, sequence2, ...) , где sequence1, sequence2 и т.д — последовательности (это аргументы функции).
Если одна из последовательностей, переданных в zip(), короче, чем остальные, то zip() остановит формирование кортежей, когда самая короткая последовательность исчерпается.
numbers = [1, 2, 3]
letters = ["a", "b", "c", "d", "e"]
zipped = zip(numbers, letters)
print(*zipped, end=" ") # (1, 'a') (2, 'b') (3, 'c')zipped = zip(numbers, letters, strict=True) , применить флаг strict, который отвечает за проверку длин переданных итераций, то в нашем примере произойдет ошибка «ValueError: zip() argument 2 is longer than argument 1». По умолчанию значение параметра установлено в strict=False .Функция zip() возвращает итератор кортежей и для понимания сути она строки превращает в столбцы, а столбцы в строки.
,
Особенности сортировки через sort() и sorted()
Для сортировки списков в Python можно использовать метод sort(). Этот метод сортирует элементы списка на месте, то есть изменяет сам список, и не возвращает никакого значения. Метод — это функция, которая принадлежит определенному объекту или классу.
Синтаксис метода: list_name.sort(key=None, reverse=False), где key — опциональный параметр, который указывает функцию для генерации ключа сортировки; reverse — также опциональный параметр, если установлен в True, сортировка будет в обратном порядке. По умолчанию методsort()сортирует элементы в порядке возрастания.
При использовании параметра key в методе sort() можно передавать любую функцию, которая генерирует ключ для сортировки элементов. Например, можно использовать встроенные функции, лямбда-функции или функции, определенные пользователем. str.lower — для сортировки строк без учета регистра, abs — для сортировки по абсолютному значению чисел, лямбда-функции для более специализированных случаев сортировки.
Метод sort() не может сравнивать элементы, которые нельзя сравнить с помощью оператора <, например строки нельзя сравнить с числом. Если вы хотите сортировать список, содержащий как строки, так и числа, вы можете использовать параметр key, чтобы указать функцию для генерации ключа сортировки. Например, вы можете использовать функцию str для преобразования чисел в строки перед сортировкой.
fruits = ["apple", "banana", "cherry", "date"]
# Сортируем список по длине каждого элемента от большей к меньшей
fruits.sort(key=len, reverse=True)
print(fruits) # Вывод: ['date', 'apple', 'banana', 'cherry']
fruits.append(777)
print(fruits) # ['banana', 'cherry', 'apple', 'date', 777]
# fruits.sort() # TypeError: '<' not supported between instances of 'int' and 'str'
fruits.sort(key=str)
print(fruits) # [777, 'apple', 'banana', 'cherry', 'date']Функцияsorted() в Python используется для сортировки элементов итерационного объекта (например, списка или др.множества) и возвращает отсортированный список. Она не изменяет исходный список, а возвращает новый отсортированный список.
Синтаксис функции sorted(): sorted_list = sorted(iterable, key=None, reverse=False), где iterable — итерационный объект, который нужно отсортировать; key — опциональный параметр, который указывает функцию для генерации ключа сортировки; reverse — опциональный параметр, если установлен в True, то сортировка будет в обратном порядке.
numbers = [5, 2, 8, 1, 4]
sorted_numbers = sorted(numbers)
print(sorted_numbers) # Вывод: [1, 2, 4, 5, 8]В Python словари не упорядочены, но элементы словаря можно сортировать по ключам или значениям.
- Сортировка по ключам: используйте функцию
sorted()с методомitems()словаря для сортировки по ключам.
my_dict = {"b": 2, "a": 1, "c": 3}
sorted_dict = dict(sorted(my_dict.items()))
print(sorted_dict) # Вывод: {'a': 1, 'b': 2, 'c': 3}- Сортировка по значениям: используйте функцию
sorted()с методомitems()словаря и параметромkeyдля сортировки по значениям.
my_dict = {"b": 2, "a": 1, "c": 3}
sorted_dict = dict(sorted(my_dict.items(), key=lambda x: x[1]))
print(sorted_dict) # Вывод: {'a': 1, 'b': 2, 'c': 3}- Сортировка по значениям в обратном порядке: используйте параметр
reverse=Trueдля сортировки в обратном порядке.
my_dict = {"b": 2, "a": 1, "c": 3}
sorted_dict = dict(sorted(my_dict.items(), key=lambda x: x[1], reverse=True))
print(sorted_dict) # Вывод: {'c': 3, 'b': 2, 'a': 1}
sorted_dict = sorted(my_dict)
print(sorted_dict) # ['a', 'b', 'c']sorted(my_dict) отдаст список с отсортированными ключами, так как словарь при итерации по умолчанию возвращает ключи.
, и
,
Аргумент key для сортировки коллекций по ключу
Для сортировки коллекций с помощью функции sorted() или метода sort(), вы можете использовать аргумент key, который определяет функцию, по которой будет происходить сортировка. Т.е. аргументу key присваивается ссылка на функцию, для простых функций в key записывают лямбда-функцию. Например, если у вас есть список словарей и вы хотите отсортировать его по значению определенного ключа, вы можете передать функцию, которая извлекает это значение в качестве аргумента key.
Например:
def sortname(family_members):
return family_members["name"]
# Список словарей для сортировки
family_members = [
{"name": "Анна", "age": 42},
{"name": "Сергей", "age": 49},
{"name": "Лев", "age": 6},
]
# Сортировка списка по ключу 'age'
sorted_family_members = sorted(family_members, key=lambda x: x["age"])
print(sorted_family_members)
# Сортировка списка по ключу 'name'
sorted2_family_members = sorted(family_members, key=sortname)
print(sorted2_family_members)и приведем еще два аналогичных интересных примера, которые потребуются для решения задач в курсе
n = [0, 2, 1]
a = ("a", "b", "c")
print(sorted(a, key=lambda x: n.index(a.index(x)))) # ['a', 'c', 'b']Мы имеем список n и кортеж a, и затем сортируем кортеж a с использованием лямбда-функции в качестве ключа сортировки. Лямбда-функция lambda x: n.index(a.index(x)) использует значения из списка n для определения порядка сортировки элементов в кортеже a. Как это происходит:
sorted(a, key=lambda x: n.index(a.index(x))) — функция sorted() сортирует элементы кортежа a с помощью лямбда-функции в качестве ключа сортировки. Лямбда-функция lambda x: n.index(a.index(x)) принимает элемент x из кортежа a и сначала находит индекс этого элемента в кортеже a с помощью a.index(x), затем находит индекс этого значения в списке n с помощью n.index(...). Это определяет порядок сортировки элементов кортежа a на основе их позиции в списке n. После выполнения этого кода будет выведен отсортированный кортеж a в соответствии с порядком, определенным лямбда-функцией.
row = ["низкий=третий", "средний=второй", "высокий=первый",]
stroi = ["первый", "второй", "третий",]
row = [x.split("=") for x in row] # [['низкий ', ' третий'], ['средний ', ' второй'], ['высокий ', ' первый']]
row = sorted(row, key=lambda x: stroi.index(x[1]))
print(row) # [['высокий', 'первый'], ['средний', 'второй'], ['низкий', 'третий']]row сортируется с использованием ключа, определенного лямбда-функцией lambda x: stroi.index(x[1]). Это означает, что сортировка будет производиться с учетом индексов элементов x[1] (то есть вторых элементов во вложенных списках row) в списке stroi.и
,
Функции isinstance и type для проверки типов данных
isinstance() — это встроенная функция в Python, которая используется для проверки принадлежности объекта к определенному классу или типу данных. Функция isinstance() возвращает True, если объект является экземпляром указанного класса или типа данных, и False в противном случае.
Синтаксис: isinstance(object, classinfo) , где object: объект, тип которого нужно проверить; classinfo: класс или тип данных, к которому нужно проверить принадлежность объекта. Функция isinstance() возвращает True, если объект является экземпляром указанного класса или типа данных, и False в противном случае.
isinstance может сравнивать определенный тип с несколькими ожидаемыми типами.
Также важно помнить, что при проверке типа bool с int также вернется True: print(isinstance(True, int)) # True
type() — это встроенная функция в Python, которая возвращает тип объекта. Она может быть использована для определения типа переменной или объекта во время выполнения программы. Функция type() возвращает объект типа type, который представляет тип объекта. Она может быть полезна для проверки типов объектов во время выполнения программы и принятия решений на основе этих типов.Синтаксис функции type() выглядит следующим образом: type(object) , где object — это объект, тип которого необходимо получить.
Что лучше: isinstance() и type() — это две разные функции в Python, которые могут быть использованы для работы с типами объектов, но с разными целями.
Вот когда лучше использовать isinstance():
isinstance()используется для проверки принадлежности объекта определенному типу или классу, а также его подклассам. Это позволяет делать более гибкие проверки типов.- Если вам нужно проверить, является ли объект экземпляром определенного класса или его подкласса, то лучше использовать
isinstance(). isinstance()позволяет обрабатывать наследование и полиморфизм, что делает его более удобным для проверки типов в сложных иерархиях классов.
Вот когда лучше использовать type():
type()просто возвращает тип объекта, без учета наследования или подклассов. Если вам нужно только получить тип объекта, а не проверять принадлежность к определенному классу, тоtype()может быть более удобным.type()полезна, когда вам нужно точно знать тип объекта без учета его наследования или других аспектов.
class Animal:
pass
class Dog(Animal):
pass
dog = Dog()
print(isinstance(dog, Dog)) # True
print(isinstance(dog, Animal)) # True
x = 5
print(type(x)) # <class 'int'>, и
,
Функции all и any. Примеры их использования
Функции all() и any() в Python являются встроенными функциями для работы с итерируемыми объектами, такими как списки, кортежи, множества и другие.
Функция all() возвращает True, если все элементы в итерируемом объекте истинны (равны True) или если итерируемый объект пуст. Если хотя бы один элемент ложный (равен False), то all() вернет False.
Функция all() применяется, когда нужно убедиться, что все элементы в итерируемом объекте удовлетворяют определенному условию. Работу функции all() можно сравнить с оператором and в Python, только all() работает с последовательностями
Обычно в функцию all() передают последовательность, полученную в результате вычислений или сравнений, элементы которого будут оцениваться как True или False. Для этого можно использовать функцию map() или выражения-генераторы списков, используя в них встроенные функции или методы, возвращающие bool значения, операции сравнения, оператор вхождения in и оператор идентичности is.
Функция any() проверяет, что хотя бы один элемент в последовательности True. Функция возвращает True, если какой-либо (любой) элемент в итерируемом объекте является истинным True, в противном случае any() возвращает значение False.
Обычно функция any() применяется в сочетании с оператором ветвления программы if ... else. Работу функции any() можно сравнить с оператором or в Python, только any() работает с последовательностями.
Обычно в функцию any() передают последовательность, полученную в результате каких то вычислений или сравнений, элементы которого будут оцениваться как True или False. Для этого можно использовать функцию map() или выражения-генераторы списков, используя в них встроенные функции языка, возвращающие bool значения, операции сравнения, оператор вхождения in и оператор идентичности is.
Разница между any() и all() заключается в том, что any() проверяет, удовлетворяют ли хотя бы один элемент условию, в то время как all() проверяет, удовлетворяют ли все элементы условию.
# Пример использования any()
values = [1, 0, 2, 0, 3]
if any(value > 0 for value in values):
print("Существует положительное значение") # сработает это
else:
print("Нет положительного значения")
# Пример использования all()
numbers = [1, 2, 3, 4, 5]
if all(number % 2 == 0 for number in numbers):
print("Все числа четные")
else:
print("Не все числа четные") # сработает этоВ этом примере Функция any() используется для проверки, есть ли хотя бы одно положительное значение в списке values. Если хотя бы одно значение больше нуля, то выводится сообщение «Существует положительное значение».Функция all() используется для проверки, являются ли все числа в списке numbers четными. Если все числа в списке делятся на 2 без остатка, то выводится сообщение «Все числа четные». В противном случае выводится сообщение «Не все числа четные».
Разница между all()и any():
all()возвращаетTrue, если все элементы итерируемого объекта истинные, в то время какany()возвращаетTrue, если хотя бы один элемент истинный.all()возвращаетTrueдля пустого итерируемого объекта, в то время какany()вернетFalseдля пустого итерируемого объекта.
Когда применять:
- Используйте
all(), когда вам нужно убедиться, что все элементы удовлетворяют условию. - Используйте
any(), когда вам нужно проверить, что хотя бы один элемент удовлетворяет условию.
и
,
Дополнительно
Для чего в python используется is
is в Python используется для сравнения объектов по их идентификаторам, то есть проверки, являются ли два объекта одним и тем же объектом в памяти. Обратите внимание, что оператор is сравнивает идентификаторы объектов в памяти, а не их значения или содержимое.
— оператор==проверяет равенство значений двух объектов
— оператор is проверяет идентичность самих объектов. Его используют, чтобы удостовериться, что переменные указывают на один и тот же объект в памяти
list1 = [1, 2, 3]
list2 = [1, 2, 3]
list3 = list1
print(list1 == list2) # True, так как оператор `==` сравнивает значения списков, которые одинаковы
print(list1 is list2) # False, так как оператор `is` сравнивает идентификаторы объектов, которые разные
print(list1 == list3) # True, так как оператор `==` сравнивает значения списков, которые одинаковы
print(list1 is list3) # True, так как list3 ссылается на тот же объект списка, что и list1Игнорирование некоторых значений с помощью символа подчеркивания ‘_’
Символ _ в Python является специальным идентификатором, который используется в различных контекстах для различных целей. один из вариантов использования — игнорирование ненужных вам значений.
x, _, y = (1, 2, 3): В этом примере символ _ используется для игнорирования значения при распаковке кортежа. Значение второго элемента кортежа игнорируется, и переменные x и y получают значения первого и третьего элементов соответственно.
x, *_, y = (1, 2, 3, 4, 5): В Python 3.x это называется «Extended Unpacking» (расширенная распаковка). Символ _ используется для игнорирования нескольких значений при распаковке кортежа. Первое и последнее значения кортежа сохраняются в переменные x и y, а все остальные значения игнорируются.
for _ in range(10): do_something(): Здесь символ _ используется в цикле for для игнорирования значения, которое не используется внутри цикла. Обычно это используется, когда переменная цикла не нужна внутри цикла.
for _, val in list_of_tuple: do_something(): В этом примере символ _ используется для игнорирования значения в конкретной позиции при распаковке кортежей из списка кортежей. Первое значение в каждом кортеже игнорируется, а второе значение сохраняется в переменную val.
lst = ((33, "a", "aa"), (44, "b", "bb"), (55, "c", "cc"), (66, "d", "dd"))
print(*(a for _, _, a in lst)) # aa bb cc dd
lst2 = [[33, "a"], [44, "b"], [55, "c"], [66, "d"]]
print(*(item for _, item in lst2)) # a b c d
print(*(item for item, _ in lst2)) # 33 44 55 66Эти примеры демонстрируют различные способы использования символа _ в Python для игнорирования значений в различных контекстах.
Расширенное представление чисел. Системы счисления
Число в экспоненциальной записи представляет собой способ записи очень больших или очень маленьких чисел с использованием степени 10. Обычно экспоненциальная запись имеет вид a * 10^b, где a — мантисса (значащая часть числа), а b — экспонента, указывающая на то, на сколько нужно умножить мантиссу на 10.
Например, число 6.022 * 10^23 в экспоненциальной записи означает, что мантисса равна 6.022, а число нужно умножить на 10 в 23 степени (то есть 6.022 * 10 * 10 * … * 10, где количество умножений равно 23).
Экспоненциальная запись часто используется в науке, инженерии и вычислительной технике для удобства представления и работы с очень большими или очень маленькими числами.
Система счисления — это способ представления чисел с использованием определенных символов или цифр, а также правил их комбинирования. Существует множество различных систем счисления, но наиболее распространенными являются десятичная (с основанием 10), двоичная (с основанием 2) и шестнадцатеричная (с основанием 16) системы.
Вот краткое объяснение каждой системы счисления:
Десятичная система:
- В десятичной системе каждая цифра может принимать одно из десяти значений (от 0 до 9).
- Каждая позиция числа в десятичной системе имеет вес, который равен степени числа 10.
- Например, число 345 в десятичной системе означает (3 * 10^2) + (4 * 10^1) + (5 * 10^0) = 300 + 40 + 5 = 345.
Пример: Первоначальное число: 1011011011. Разложение: 1 * 2^9 + 0 * 2^8 + 1 * 2^7 + 1 * 2^6 + 0 * 2^5 + 1 * 2^4 + 1 * 2^3 + 0 * 2^2 + 1 * 2^1 + 1 * 2^0. Результат: 731 в десятичной системе.
Двоичная система:
- В двоичной системе каждая цифра может принимать одно из двух значений (0 или 1).
- Каждая позиция числа в двоичной системе имеет вес, который равен степени числа 2.
- Например, число 101 в двоичной системе означает (1 * 2^2) + (0 * 2^1) + (1 * 2^0) = 4 + 0 + 1 = 5.
Префикс 0b указывает на то, что число следующее за ним записано в двоичной системе.
Пример: Разберем 0b1010: Число 1010 в двоичной системе означает 1 * 2^3 + 0 * 2^2 + 1 * 2^1 + 0 * 2^0, что равно 10 в десятичной системе. Таким образом, 0b1010 в двоичной системе равно десятичному числу 10.
Восьмеричная система:
- В восьмеричной системе каждая цифра может принимать одно из восьми значений (от 0 до 7).
- Каждая позиция в восьмеричной системе имеет вес, который является степенью числа 8.
- Например, число
347в восьмеричной системе означает 3 * 8^2 (8 в квадрате) + 4 * 8^1 (8 в степени 1) + 7 * 8^0 (8 в нулевой степени) и равно 231 в десятичной системе.
Префикс 0o используется для обозначения чисел, записанных в восьмеричной системе счисления.
Пример: Разберем число 0o34: число 34 в восьмеричной системе означает 3 * 8^1 + 4 * 8^0. Раскрывая умножения и складывая, получаем: 24 + 4 = 28. Таким образом, число 0o34 в восьмеричной системе равно десятичному числу 28.
Шестнадцатеричная система:
- В шестнадцатеричной системе каждая цифра может принимать одно из шестнадцати значений (от 0 до 9 и от A до F).
- Шестнадцатеричная система широко используется в программировании для представления байтов и цветов.
- Например, число 1A в шестнадцатеричной системе означает (1 * 16^1) + (10 * 16^0) = 16 + 10 = 26.
Префикс 0x используется для обозначения чисел, записанных в шестнадцатеричной системе счисления.
Пример: Разберем число 0x1A, здесь 1A в шестнадцатеричной системе означает 1 * 16^1 + 10 * 16^0. Раскрывая умножения и складывая, получаем: 16 + 10 = 26.
Восьмеричная система широко использовалась в прошлом в компьютерах и программировании, но сейчас наиболее распространены десятичная, двоичная и шестнадцатеричная системы. Каждая система счисления имеет свои особенности и используется в различных областях. Понимание систем счисления важно для работы с числами и выполнения математических операций в различных контекстах, таких как программирование, электроника и т.д.
,
Битовые операции И, ИЛИ, НЕ, XOR. Сдвиговые операторы
В Python поддерживаются следующие битовые операторы:
& — Битовый оператор «И» (AND)
| — Битовый оператор «ИЛИ» (OR)
^ — Битовый оператор «Исключающее ИЛИ» (XOR)
~ — Битовый оператор «НЕ» (NOT)
<< — Битовый оператор сдвига влево
>> — Битовый оператор сдвига вправо
Эти операторы позволяют выполнять побитовые операции с числами.
Битовые операции могут быть более быстрыми, чем их аналоги на уровне высокоуровневых операций, в некоторых случаях. Однако, в современных компиляторах и интерпретаторах языков программирования, оптимизации могут автоматически применяться к высокоуровневым операциям, что делает их эффективными и быстрыми.
Битовые операции могут быть особенно полезны в случаях, когда необходимо выполнить манипуляции с битами напрямую, такие как маскирование, проверка флагов, шифрование и другие низкоуровневые операции. В таких случаях использование битовых операций может быть эффективным и быстрым способом решения задач.
Однако, при разработке программного обеспечения важно учитывать не только скорость выполнения операций, но и читаемость и другие аспекты кода.
p.s. решение задач по этой теме я пропустил, т.к. думаю, что битовые операции для меня наверняка в ближайшее время будут невостребованные.
,
Модуль random стандартной библиотеки
Модуль random в Python предоставляет функции для генерации случайных чисел. .
Вот некоторые основные функции и возможности модуля random:
random(): Функция random() возвращает случайное число с плавающей запятой в диапазоне от 0.0 до 1.0 (включая 0.0, исключая 1.0).
uniform(a, b): Функция uniform(a, b) возвращает случайное число с плавающей запятой в диапазоне от a до b. Функция uniform() полезна в ситуациях, когда необходимо получить случайное число в определенном числовом диапазоне с плавающей запятой.
randint(a, b): Функция randint(a, b) возвращает случайное целое число, которое является равномерным распределению в диапазоне от a до b, включая границы этого диапазона.
randrange(start, stop, step) : Функция возвращает случайное целое число из диапазона, начиная с start (включительно) и заканчивая stop (не включая), с шагом step. Если step не указан, по умолчанию он равен 1. Функция random.randrange() позволяет гибко задавать начальное значение, конечное значение и шаг при генерации случайных чисел в заданном диапазоне.
Генерация чисел в описанных функциях идет по равномерному закону, это означает, что вероятность получения любого конкретного числа в диапазоне равна для всех чисел в этом диапазоне, это обеспечивает равномерность распределения результатов и отражает отсутствие предвзятости в выборе конкретных значений.
Функция gauss(mu, sigma) из модуля random в Python возвращает случайное число с плавающей запятой, которое распределено по нормальному (гауссовскому) закону с указанным средним значением mu и стандартным отклонением sigma. Функция полезна, когда вам нужно сгенерировать случайные значения, которые следуют нормальному распределению. Это может быть полезно, например, для моделирования случайных данных, статистических исследований и других задач, где необходимо учитывать нормальное распределение случайных переменных.
Распределение по нормальному (гауссовскому) закону — это распределение вероятностного распределения, в котором значения имеют нормальную ( bell-образную ) форму. Это распределение широко используется в статистике и математической физике. В нормальном распределении среднее значение (ожидаемое значение) определяется как mu, а стандартное отклонение (стандартное расстояние) определяется как sigma.
choice(seq): Функция choice(seq) возвращает случайный элемент из непустой последовательности seq. Функция удобна, когда вам нужно выбрать случайный элемент из заданного списка, кортежа или другой последовательности.
shuffle(seq): Функция shuffle(seq) перемешивает элементы последовательности seq в случайном порядке. Функция полезна, когда вам нужно случайным образом изменить порядок элементов в списке, например, для случайной перестановки элементов или для подготовки данных для случайного выбора. Она применена к различным изменяемым последовательностям, но для неизменяемых последовательностей, как кортежи, нужно сначала преобразовать их в список.
sample(population, k): Функция sample(population, k) возвращает список из k уникальных элементов из population.
Функция random.seed() из модуля random в Python используется для установки начальной точки генератора случайных чисел (задает его начальное состояние). Она позволяет управлять генерацией случайных чисел и обеспечивает воспроизводимость результатов.
Приведем пример с перечисленными функциями:
import random
# Генерация случайного числа с плавающей запятой между 0.0 и 1.0
random_number = random.random()
print(random_number)
# Генерация случайного числа с плавающей запятой между 2.5 и 5.5
random_float = random.uniform(2.5, 5.5)
print(random_float)
# Генерация случайного целого числа между 1 и 10
random_integer = random.randint(1, 10)
print(random_integer)
# Генерация случайного числа в диапазоне от 0 до 10 (не включая 10) с шагом 2
random_number = random.randrange(0, 10, 2)
print(random_number)
# Генерация случайного числа по нормальному закону с mu=0 и sigma=1
random_number = random.gauss(0, 3)
print(random_number)
# Выбор случайного элемента из списка
my_list = [1, "tt", 3.5, 4, 5]
random_element = random.choice(my_list)
print(random_element)
# Возвращаем список из 3х случайных элементов списка
my_list = [1, "tt", 3.5, 4, 5]
random_item = random.sample(my_list, 3)
# Перемешивание элементов в списке
random.shuffle(my_list)
print(my_list)
# Установка начального значения для генератора случайных чисел
random.seed(42)
random_number = random.randint(1, 10) # Генерация случайного числа имеет предсказуемый порядок
print(random_number), , , и
,
Аннотация базовыми типами
Динамическая типизация в Python — это свойство языка, которое позволяет изменять тип переменных во время выполнения программы. Это означает, что тип переменной может быть изменен во время выполнения программы, в зависимости от значения, присвоенного этой переменной.
Аннотация типов в Python — это возможность языка, которая позволяет явно указывать типы переменных, аргументов функций и возвращаемых значений. Это не обязательное требование для Python, но может быть использовано для улучшения читаемости кода, облегчения его поддержки и уменьшения вероятности ошибок.
Аннотации типов в Python обычно используются с помощью синтаксиса под названием «Type Hints» (подсказки типов), который введен в Python 3.5. Этот синтаксис позволяет указывать тип переменной с помощью двоеточия после имени переменной, например: x: int = 5
Использование аннотаций типов помогает разработчикам и инструментам статического анализа кода понимать ожидаемые типы данных, что может быть полезно для обнаружения потенциальных ошибок во время разработки. Аннотация типов носит информационный характер и не влияет на само выполнение кода, так как Python динамически типизированный язык.
Аннотации типов применяют для:
- Улучшение читаемости кода: Аннотации типов делают код более ясным и понятным, позволяя разработчикам быстрее понимать, какие типы данных ожидаются в различных частях кода.
- Помощь в документировании кода: Аннотации типов могут быть использованы для документирования кода, указывая ожидаемые типы данных для переменных, аргументов функций и возвращаемых значений.
- Помощь статическому анализу кода: Аннотации типов облегчают статический анализ кода, позволяя инструментам анализировать код на предмет потенциальных ошибок типов на этапе разработки.
- Облегчение совместной работы: Использование аннотаций типов может помочь другим разработчикам в команде быстрее разбираться в коде, особенно в больших проектах.
- Улучшение надежности кода: Аннотации типов могут помочь предотвратить некоторые типичные ошибки, связанные с неправильными типами данных, на этапе разработки.
Пример аннотации типов для функции, ожидающей два аргумента типа int и возвращающей значение типа int:
def add(x: int, y: int) -> int:
return x + yx: int и y: int указывают, что x и y должны быть целыми числами, а -> int аннотирует возвращаемый тип, т.е. указывает, что функция будет возвращать целое число.
Модуль typing в Python предоставляет инструменты для аннотации типов и поддержки статической типизации, typing является частью стандартной библиотеки Python.
Модуль typing предоставляет тип Union, который позволяет объединить несколько типов данных в один.
from typing import Union
def display_value(value: int | float | str) -> None:
print(value)
# можно и так
# def display_value(value: Union[int, float, str]) -> None: print(value)Модуль typing предоставляет тип Optional, который позволяет указать, что переменная может быть определена как определенный тип данных или None.
typing.Any — это специальный тип данных в модуле typing в Python, который представляет любой тип данных.
Тип typing.Final в модуле typing в Python используется для указания, что переменная является «финальной» (immutable) и не может быть изменена после присваивания значения.
, и
,
Аннотации типов коллекций
Для аннотации списков в Python с помощью модуля typing можно использовать тип List.
,
Аннотации типов на уровне классов
,
Конструкция match/case. Первое знакомство
В Python существует новая конструкция match/case, которая была добавлена начиная с версии Python 3.10. Эта конструкция предоставляет возможность делать сопоставление с образцом, что облегчает работу с различными вариантами значений.

В конструкции должен быть хотя бы один блок case. В блоке case должен быть хотя бы один оператор. Шаблоны в блоках case могут содержать несколько значение, которые перечисляют через '|' (или). Например case 7 | 10: означает: значение равно 7 или 10.
case _:, обозначает значением по умолчанию, т. е. если не один шаблон не подошел, то выбирается case _: (работает как оператор else без условия).
В шаблонах также можно задавать проверку типов.
cmd = 1.99
match cmd:
case str() as command:
print(f"строка: {command}")
case 12:
print(f"двенадцать")
case float() | int() as Q if 0 < Q < 3:
print(f"число от 0 до 3:{Q}")
case int(Q):
print(f"число :{Q}")
case _: # wildcard
print(f"другая переменная")В примере мы используем конструкцию match для сопоставления значения cmd с различными вариантами. Первый case проверяет, является ли значение cmd строкой. Если это так, то переменная command будет содержать значение cmd в виде строки. Затем выводится сообщение «строка: {command}», где {command} будет заменено на значение cmd. Второй case проверяет, равно ли значение cmd 12. Если это так, то выводится сообщение «двенадцать». Третий case использует сочетание float() | int() для проверки, что значение cmd является либо числом с плавающей точкой, либо целым числом. Переменная Q содержит значение cmd, если оно удовлетворяет условию 0 < Q < 3. Если условие выполняется, то выводится сообщение «число от 0 до 3: {Q}». Четвертый case проверяет, может ли значение cmd быть преобразовано в целое число с помощью функции int(). Если это возможно, то переменная Q будет содержать преобразованное значение cmd. Затем выводится сообщение «число: {Q}», где {Q} будет заменено на преобразованное значение cmd. Пятый case использует подстановочный знак _, который соответствует любому значению, которое не было в предыдущих case. Внутри этого case выводится сообщение «другая переменная».
,
Конструкция match/case с кортежами и списками
Кроме перечисленного ранее функционала, с помощью match/case можно распаковывать кортежи и списки. В конструкции match/case для этого используют * . После * также может быть имя _, следовательно (x, y, *_) соответствует последовательности по крайней мере из двух элементов без привязки остальных элементов.
data = ("integer", 49, True, 828282)
data = ("string", "Привет, мир!")
match data:
case ("integer", int_value, *_):
print(f"Целое число: {int_value}")
case ("string", str_value) if len(str_value) > 5:
print(f"Строка: {str_value}")
case _:
print("неизвестный тип данных"),
Конструкция match/case со словарями и множествами
В отличие от списков и кортежей в шаблоне case важно только наличие ключа(ей) словаря, любые отсутствующие в case ключи, которые есть в исходном словаре, игнорируются.
data = {"name": "Сергей", "old": 49, "hobby": "agriculture"}
match data:
case {"name": "Антон", "old": int_value}:
print(f"Этому человеку лет: {int_value}")
case {"old": int_value, "hobby": "agriculture"} if int_value > 45:
print(f" в {int_value} его хобби agriculture")
case _:
print("нет подходящих людей")В примере: первый case сопоставляет словарь, у которого ключи "name" и "old" имеют конкретные значения. Если имя равно «Антон», то выводится сообщение с возрастом этого человека; второй case сопоставляет словарь, у которого ключ "old" равен определенному значению и ключ "hobby" равен «agriculture», при этом возраст должен быть больше 45. Если условие выполняется, выводится сообщение о хобби человека. И последний case _: срабатывает, когда ни одно из предыдущих сопоставлений не выполнено. В данном случае выводится сообщение о том, что нет подходящих людей в словаре.
,
Конструкция match/case. Примеры и особенности использования
Примеры использования конструкции match/case, а также использование констант внутри блоков case разобраны в уроке по ссылкам ниже
,
Итоги
Ура! Я закончил этот курс, ровно за один месяц — день в день! Когда брался за него, я думал о куда как более быстром темпе и сроках прохождения, но сегодня, уже пройдя этот курс, я сознаю, что для меня даже месяц — это почти как подвиг. И без режима «гонки» потребовалось бы куда как больше времени. Кроме того за этот же месяц был создан и этот конспект.
Мой огромный респект и благодарность автору курса — хорошая подача материала, а главное — отличные задачи по темам, от которых Python порой для меня превращался в некое подобие гадюки). Да, и это было бесплатно! Если Вы только погружаетесь в изучение языка, то это то, что Вам необходимо. Если появляется желание бросить курс из-за задач — смело пропускайте самые сложные и двигайтесь дальше. Но решить большую их часть — надо!
Мои достижения – получен сертификат с отличием и результатом в 98%, решено полтысячи задач, получено 900 баллов из 917 возможных. Решено всё, кроме всех задач из раздела «Битовые операции». Также из-за тупикового состояния я вынужден был искать в интернете решения по 4 задачам и потом просто вникал, что и как в них было реализовано. Сейчас главное не утратить полученные навыки, т.к. по некоторым темам уже кое-что забывается. Но благо у меня теперь есть этот конспект, который для меня стал и учебником и справочником, а это 2150 строк, почти 250тыс знаков, более 200 ссылок. Здесь всё на одной странице и с множеством ссылок на «подробности». Я буду рад, если и Вам он пригодится.
Что дальше? Ну видимо нужно будет снова пройтись хотя бы по верхам ООП (ранее начинал смотреть ООП и отложил тему, поняв что сначала нужно знать базу). И однозначно для технического анализа надо будет изучить Pandas, т.к. оперировать с тысячами данных OHLCV с помощью обычных множеств Python представляется достаточно сложным и малоэффективным мероприятием.
Всем успехов в освоении Python!







